
数据库工具解析之 OceanBase 数据库导出工具
是为OceanBase的用户介绍一下OceanBase自研的数据库导出工具——obdumper。让大家了解导数工具的发展历程和现状。
背景
大多数的数据库都配备了自己研发的导入导出工具,对于不同的使用者来说,这些工具能够发挥不一样的作用。例如:DBA可以使用导数工具进行逻辑备份恢复,开发者可以使用导数工具完成系统间的数据交换。这篇文章主要是为OceanBase的用户介绍一下OceanBase自研的数据库导出工具——obdumper。让大家了解导数工具的发展历程和现状。
官方文档说明过 obdumper 使用Java语言开发的,这里之所以选择Java语言,主要是为了解决跨平台的问题。毕竟平台适配相关的工作也是一件比较烦的事儿,事实上已经有用户咨询过 obdumper 是否可以直接运行在 x86, arm 等平台,似乎一切都在当初语言选择的预料之中。虽然 OceanBase 对于 MySQL/Oracle 的内核特性具备较高的兼容性,但是开源的 MySQL/Oracle 生态工具是不推荐使用的,因其没有更好地兼容 OceanBase 内核的行为。我们没有选择魔改开源工具,而是选择自研的目的就是为了让其变得更加贴身。除此以外,也希望能够随着 OceanBase 自身业务的发展而能做到任意扩展。下面我们会从不同的角度来介绍这款工具。
核心功能
简单说介绍几个功能的应用场景:
- 导出过去某个时间点的历史快照数据,便于后期的系统降级回滚;
- 导出一张表中满足指定条件的数据,定期导出数据进行业务分析;
- 导出的表数据文件进行高压缩处理,降低长期备份归档存储成本;
- 导出整库的数据定期进行备份归档,为了系统灾备或者合规审计;
- 导出的数据进行加工处理,例如:转换、脱敏等。合规使用数据;
上述功能是不是经常用在日常的开发、测试、运维等工作中?既要满足业务,又要与时俱进。以文件压缩来讲,常见的数据导出工具是将数据导出成CSV文件,再进行后置压缩,压缩效果并不好。为了让开发环境能够使用与生产相近的数据,可以对导出的数据进行脱敏,再导入到开发库中。导数工具的目标就是让数据能够在企业内部高效地流动起来,充分发挥业务数据应有的价值。
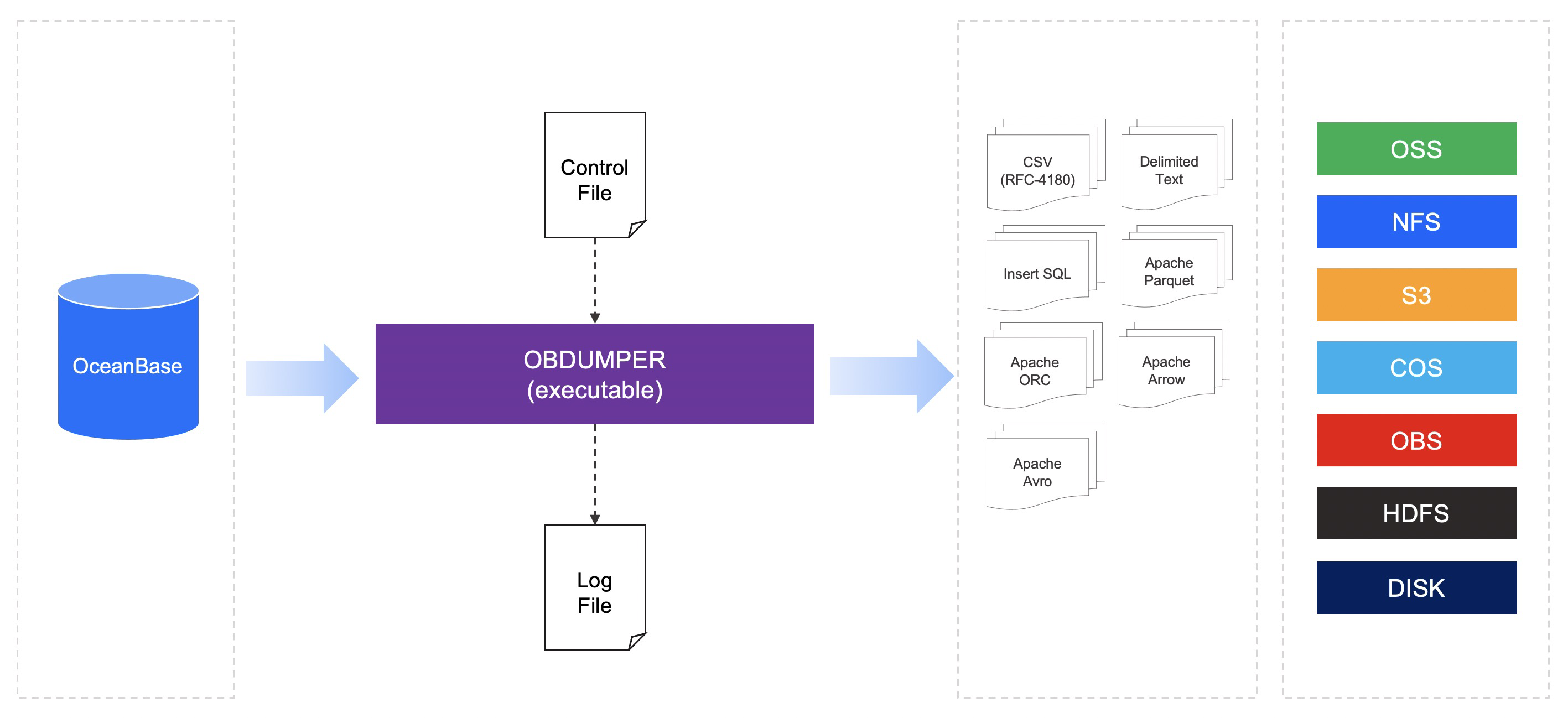
架构原理
obdumper 内部基于业务schema的定义设计了一套非常丰富的表数据切分策略(或者叫分片策略),一个库或者一张表进行多任务并行化处理,大幅提升数据的导出性能。当然,影响性能的因素有很多,例如:表结构设计,数据传输网络,数据落盘的IO 等。整体的框架是面向格式和存储进行扩展,像CSV,SQL等面向行存储的格式便于小数据量业务直接使用,例如:Excel 直接打开文件进行查看、分析;像ORC, Parquet 等面向列存储的格式可以存放大规模的表数据。同时,我们也将会支持将数据导出到不同的存储介质,让数据与存储充分解耦,促进数据跨平台的流动性。大致的架构如下图所示:

提醒:我们强烈建议用户设计表结构时,为表添加主键。表的数据量庞大时,还要对表进行分区化改造,并且保证每一个分区内的数据相对均衡。
性能测试
使用TPC-H 100GB测试库按照不同的文件格式进行导出,由于 ORC/Parquet 导出过程中默认开启压缩,所以数据导出性能比CSV/SQL格式略低一些。实际业务中牺牲一点性能换取更低的存储空间,大多数用户还是能接受的。导出测试性能图表如下:

压缩测试

整库100GB数据按照 ORC/Parquet 格式导出,默认采用zstd压缩大约是 4 : 1。如果对 CSV 文件中相同的数据采用后置压缩,压缩率远远达不到这么高。压缩率高低,不仅与压缩算法相关,也与数据的特征也有很大的关系。不同的业务数据采用相同的算法进行压缩后的效果差异也很明显,建议用户以实际的业务数据进行压缩为准。(压缩率的计算公式:Compression Ration ≈ Uncompressed Size/Compressed Size)
相关文档
官方文档: 导数工具

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐


 27
27 0
0- 0



 已为社区贡献559条内容
已为社区贡献559条内容

所有评论(0)