
打造高效实时数仓,从Hive到OceanBase的经验分享
鉴于初期采用的数据仓库方案面临高延迟、低效率等挑战,我们踏上了探索新数仓解决方案的征途。本文分享了我们从Hive到OceanBase的方案筛选与实施过程中的经验总结,期望能为您提供有价值的参考与启示。
本文作者:Coolmoon1202,大数据高级工程师,专注于高性能软件架构设计
我们的业务主要围绕出行领域,鉴于初期采用的数据仓库方案面临高延迟、低效率等挑战,我们踏上了探索新数仓解决方案的征途。本文分享了我们在方案筛选与实施过程中的经验总结,期望能为您提供有价值的参考与启示。
旧方案:(Hive + Spark)的三个挑战
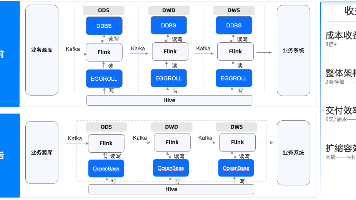
线上业务环境主要以数据统计与查询分析为主,数据来源主要有两部分:一部分是通过前端应用采集,采集到的实时流数据先存储在消息队列中,使用Spark Streaming任务每10分钟定期同步Kafka数据到Hive数据仓库。这部分数据规模较大,最大的表数据量在百亿级。
另一部分是通过政务数据共享交换平台获取,汇聚后存储在前置库RDS中,通过Spark任务定期全量同步到Hive数据仓库。这部分数据规模较小,最大的表数据量在千万级。当各种源端数据汇总在 Hive 环境之后,使用 Spark 读取数据并在大数据集群进行分析计算。
使用这样的业务方案(Spark + Hive方案)存在三个挑战。
1.实时业务的挑战:数据定时导入Hive数据仓库,无法做到实时更新,数据时延10分钟以上;
2.复杂度的挑战:数据定期从RDS全量导入Hive时,导入速度较慢,导入一次千万的表需要3分钟上;
3.成本效率的挑战:使用Spark读取Hive进行数据分析统计时,一次上亿数据的统计需要3分钟以上;使用Spark进行数据定期导入与分析统计,消耗大数据集群CPU,内存资源较高,同一时间任务太多时需要排队执行。
为解决上述挑战,我们尝试用轻量级的实时数仓解决方案。由于此前对国产原生分布式数据库 OceanBase 有所耳闻,该数据库具备HTAP特性且满足实时数仓所要求的海量数据实时写入、实时更新、实时分析的特性。当我们得知其在2021年6月已经正式开源,就决定对 OceanBase 社区版3.1.1版本进行性能测试,测试详情见《OceanBase 社区版V3.1.1压力测试情况》(仅供参考)。
测试的结论是:在当前测试环境下,按照TPC-C标准进行测试,最高可达355,739 TpmC,最快可以在24.05秒完成整个TPC-H的测试SQL执行,说明OceanBase开源版V3.1.1在OLTP与OLAP场景下都有不俗的表现,并可通过横向扩展满足大部分海量数据高并发业务场景的性能需求。
除 OceanBase 数据看库外,我们也对TiDB、PloarDB-X进行了性能测试与综合评估,OceanBase 社区版在TPC-H性能测试下和内部真实业务压力下的表现最佳。经过内部评估,OceanBase 满足目前业务需求且 OceanBase 开源社区提供了良好的技术服务与支持,最终决定尝试使用 OceanBase 社区版作为实时数仓业务的解决方案。
新方案:(OceanBase+Flink)的部署与成效
经过一段时间的方案选型与测试评估后,我们最终决定使用 OceanBase 社区版3.1.3版本替换原来的Hive数据仓库,OceanBase 集群架构选择3-3-3。
- 硬件配置:ECS 9 台,32核128G内存,每台ECS挂载两块硬盘,一块500G SSD硬盘,用于保存数据库redo日志,另一块4T SSD硬盘,用于保存数据库数据。
- 资源分配:OBServer的memory_limit为102G,system_memory为30G,OBProxy内存为4G。OceanBase 集群部署成功后,修改sys租户资源为4核4G,新建业务租户分配资源26核64G,primary_zone设置为RANDOM,让业务租户表分区的Leader随机分配到这9台ECS中。
最初计划使用OCP部署 OceanBase 集群,但由于安装OCP需要依赖 OceanBase数据库,所以最终决定使用OBD进行部署,不过后期可以通过 OCP 来接管 OBD 部署的集群,这个过程也很方便。下图为 OceanBase 集群部署拓扑图。

使用新方案(OceanBase+Flink方案)后,成效显著,主要表现为以下三个方面。
第一,端到端数据链路时延从分钟级缩短到 3秒内。数据同步从Hive+Spark模式迁移到 OceanBase+Flink模式后,数据查询与分析业务也从Hive+Spark模式迁移到 OceanBase SQL模式。业务迁移后,数据从前端应用产生到从OceanBase查询出来,端到端链路时延降低到3秒以内,而之前由于数据是从Kafka定期同步到Hive,再用Spark从Hive查询出来,至少需要10分钟的时间。
第二,硬件成本收益明显。RDS数据同步由Spark定期全量同步到Hive改成了使用Flink CDC实时增量同步到 OceanBase 后,增量模式的流任务对资源占用由抖动变得平滑,通过Flink session模式,减少了增量数据同步流任务资源空占,从而大幅度降低了大数据集群的资源占用,所需大数据集群资源从140核280G降低到23核46G,硬件成本下降84%。
第三,SQL 查询时间从分钟级到秒级。将Spark+Hive查询统计任务改成OceanBase 的SQL语句后,开启SQL分布式执行的并行Hint,6000万左右的数据查询统计(select /*+ parallel(36) */ count(1) from health_query_log where datetime >='2022-05-01 00:00:00' and datetime<='2022-06-01 00:00:00'; )在15秒内完成,而之前需要3分钟,因此统计SQL执行时间从3分钟降低至 15秒。
选择 OceanBase 的实践总结
在我们将OceanBase社区版作为实时数仓的使用过程中,总结了OceanBase社区版在该业务下的一些使用实践,供大家参考。
1. 表的创建删除索引速度较快,这样可以根据业务需求按需进行索引创建,从而大幅提高数据检索效率。
2.支持丰富的窗口函数,可以满足较为复杂的查询与统计需求。
3.支持JSON数据类型,可以直接从JSON数据中提取所需数据并创建虚拟列,从而当上游数据结构发生变化后也不需要重跑历史数据,非常好用。
4.在多表 join 情况下,尤其是使用 TableGroup功能后查询速度更快,强烈推荐。
5.OceanBase 社区版兼容 MySQL 5.7 的绝大部分功能和语法,极大地降低了开发人员的学习成本,在RDS数据同步过程中基本上没有遇到兼容性问题,迁移过程顺利。
此外,在实际使用中发现一些当前 OceanBase 社区版不支持或有计划支持的功能,目前已提交社区进行下一步迭代:
1. 暂不支持全文索引,当遇到需要对中文字符串进行模糊查询时,需要对全表进行扫描。比如,需要用家庭住址的部分信息进行模糊查询时,可使用 MySQL 的 FullText索引,然而迁移到 OceanBase 后,则无法利用全文索引来提高查询性能,当前使用 like 模糊匹配临时绕过。经过和社区官方技术团队沟通,OceanBase 计划在后续版本中进行支持。
2. 暂不支持物化视图,对于一些大表(亿级别以上)无法进行数据实时增量统计。比如对大表进行 count + group by操作时,因每次都要进行全量数据的计算,不能利用物化视图的预计算特性来降低每次查询时的数据计算量,导致部分场景计算速度达不到预期的效果。因此,当对海量数据统计实时性要求很高时,不得不寻求其他解决方案。
3. 可能导致该语句执行时,OceanBase 节点内存OOM而引起节点宕机的风险,可以通过改写子查询select count(*) from (select distinct ...)来规避此问题。
最后,感谢 OceanBase 社区技术人员对本次项目的技术支持。在我们进行OceanBase 社区版的部署、测试、迁移、使用及运维的各个阶段中,对我们提出有关 OceanBase 的各方面问题都进行了耐心与及时的解答,针对系统执行较慢的SQL统计语句也给出了优化建议,从而保证了业务实时数仓改造的顺利进行。预祝 OceanBase 社区发展越来越红火。

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐

 19
19 0
0- 0



 已为社区贡献568条内容
已为社区贡献568条内容

所有评论(0)