
客如云:大型业务报表的分区化改造提升性能|OceanBase 应用实践
随着客户增长,在处理大型报表和跨长时间范围的查询时,性能出现了瓶颈。OceanBase 分区化改造的上线,客如云智享版报表的大部分查询性能问题得到了有效缓解。
一 概述
1 背景
在过去两到三年的时间里,客如云的KPOS产品在商户数量和订单量均实现了数倍的增长,充分展示了产品的市场吸引力和业务模式的成功。然而,随着更多的大型连锁商户的加入,客如云商家平台迎来了前所未有的挑战。特别是在为这些大商户提供数据报表服务的过程中,我们遇到了一个关键问题:原有的解决方案在处理大型报表和跨长时间范围的查询时,性能出现了瓶颈。
顺应业务增长的需求,我们的技术团队迅速反应,深入剖析了面临的性能挑战,并采取了一系列切实有效的技术优化措施,以确保即使在数据量剧增的情况下也能保持流畅的查询体验。我们的优化措施主要集中在以下几个方面:
- 数据库性能:我们对数据库架构进行了全面优化,包括引入并行技术、优化索引、以及实施适当的数据拆分策略、查询逻辑优化等,从而减少了数据库负载并提高了查询效率和系统的扩展能力。
- 异步处理:对于数据量巨大的报表,我们采用了异步生成并通过后台任务队列处理,允许用户在报表准备就绪后再进行查看,极大提升了前端体验。
- 报表预生成:我们还实现了对常用报表的预生成和定期更新机制,确保了用户可以快速获取最常查看的报表数据。
经过这些技术层面的努力优化,我们的报表系统现已能够稳定地支持日单量近千万的业务需求。但我们的团队意识到,随着业务不断发展壮大,技术挑战也会不断涌现,因此我们将持续投资于技术创新和性能提升,致力于为KA商户提供无与伦比的服务体验。
除业务层面面临的问题,同时也对运维团队提出了前所未有的挑战。在技术运维方面,我们面临两个主要的瓶颈:数据库服务器的扩容受限,以及大表变更的困难。
- 数据库服务器的扩容问题表现在两个方面:物理资源已到达上限和扩容过程中的服务断连风险。由于现有硬件资源的限制,对数据库服务器进行垂直扩展(增强单个服务器的性能)已到达瓶颈,而水平扩展(增加更多服务器)也受到了当前数据库部署架构的限制。
- 随着数据量的飞速增加,我们的数据库中出现了大量的大表。这些大表的变更,无论是结构调整还是数据迁移,都变得异常复杂和耗时。每次变更都需要在保持高可用性和最小化影响的前提下进行,这对运维团队的技能和资源配置提出了巨大挑战。变更操作通常涉及详细的计划,以及在执行期间实施详尽的监控以确保对商户无感操作。
2 现状
2.1 业务情况
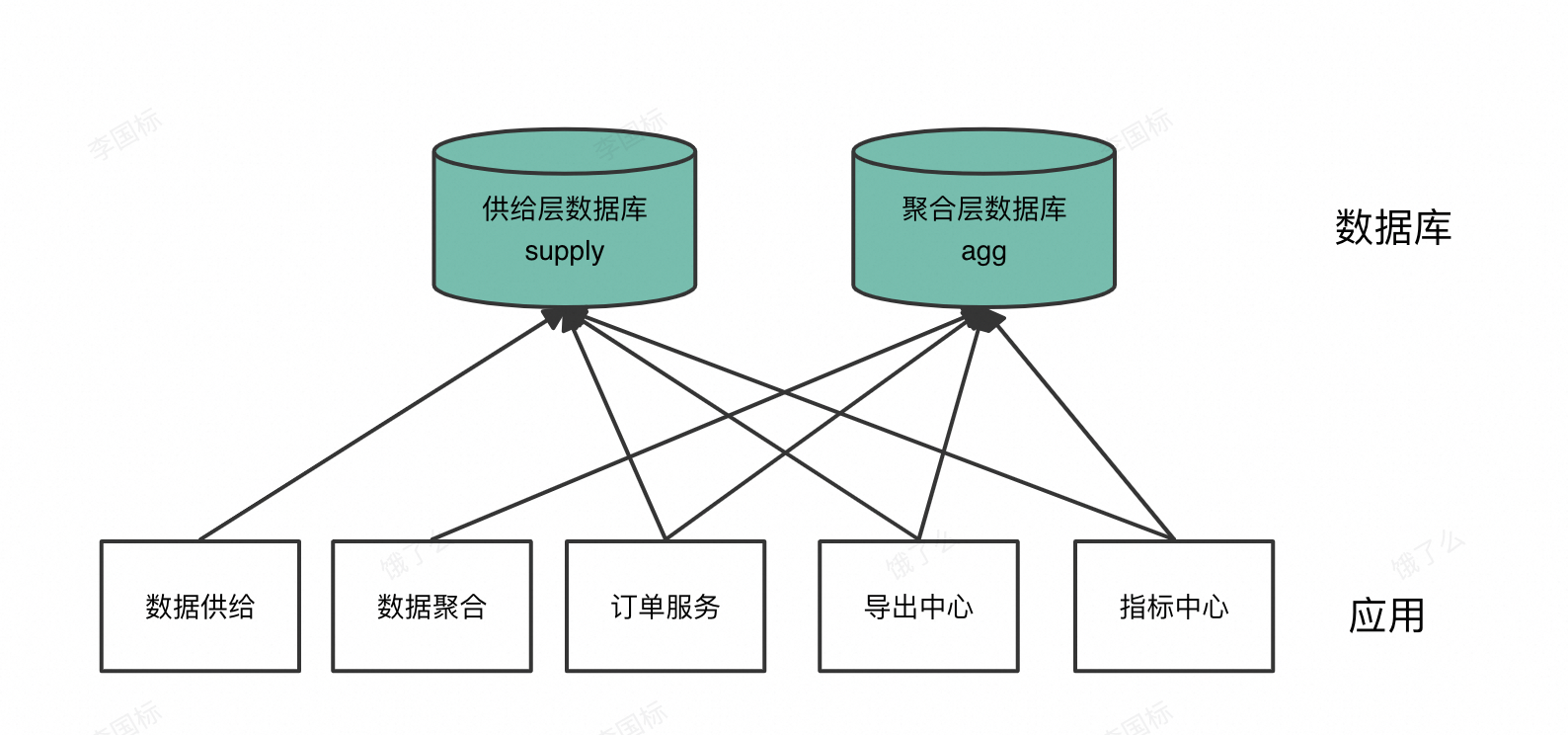
- 应用链接数据库
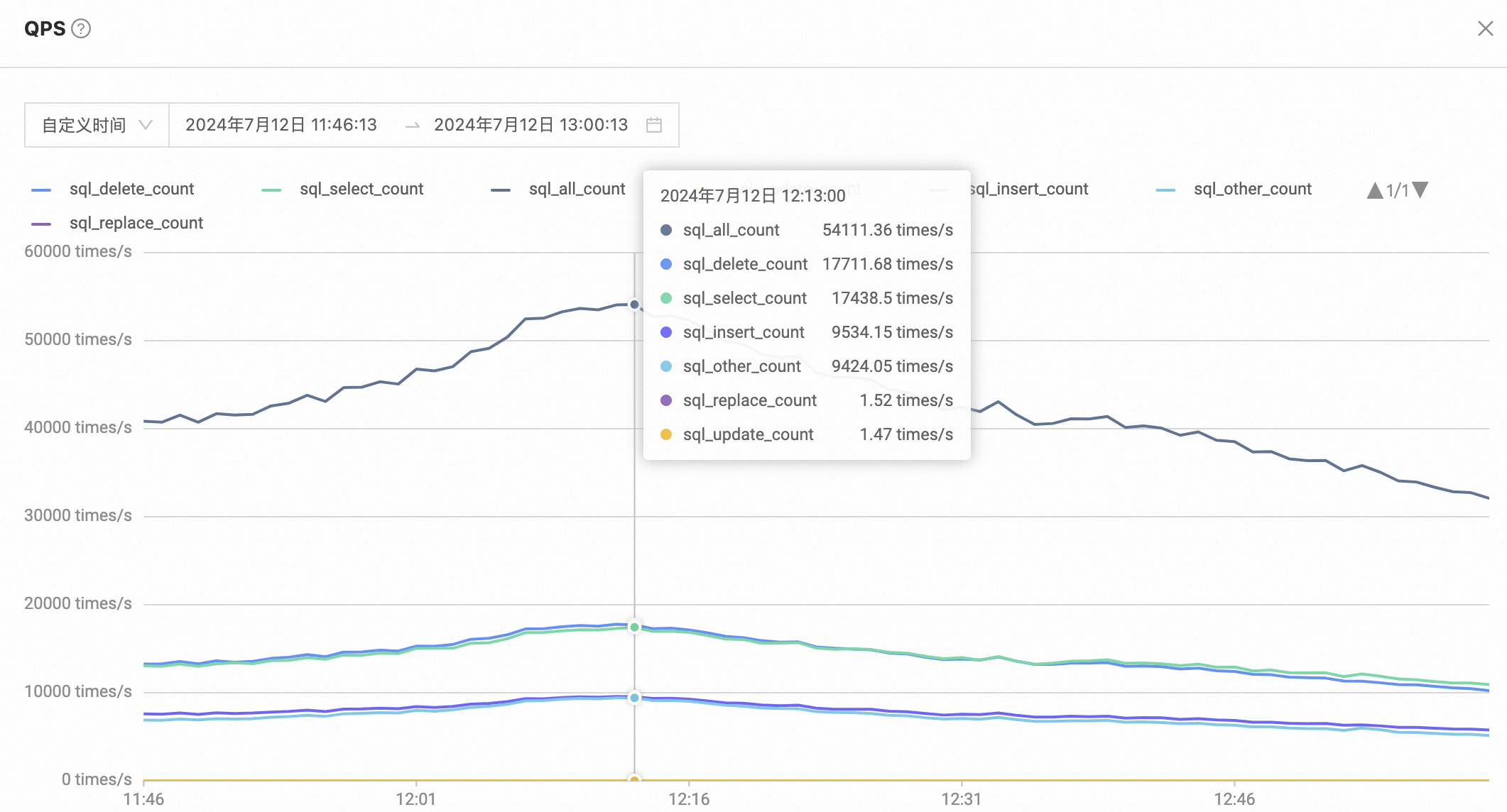
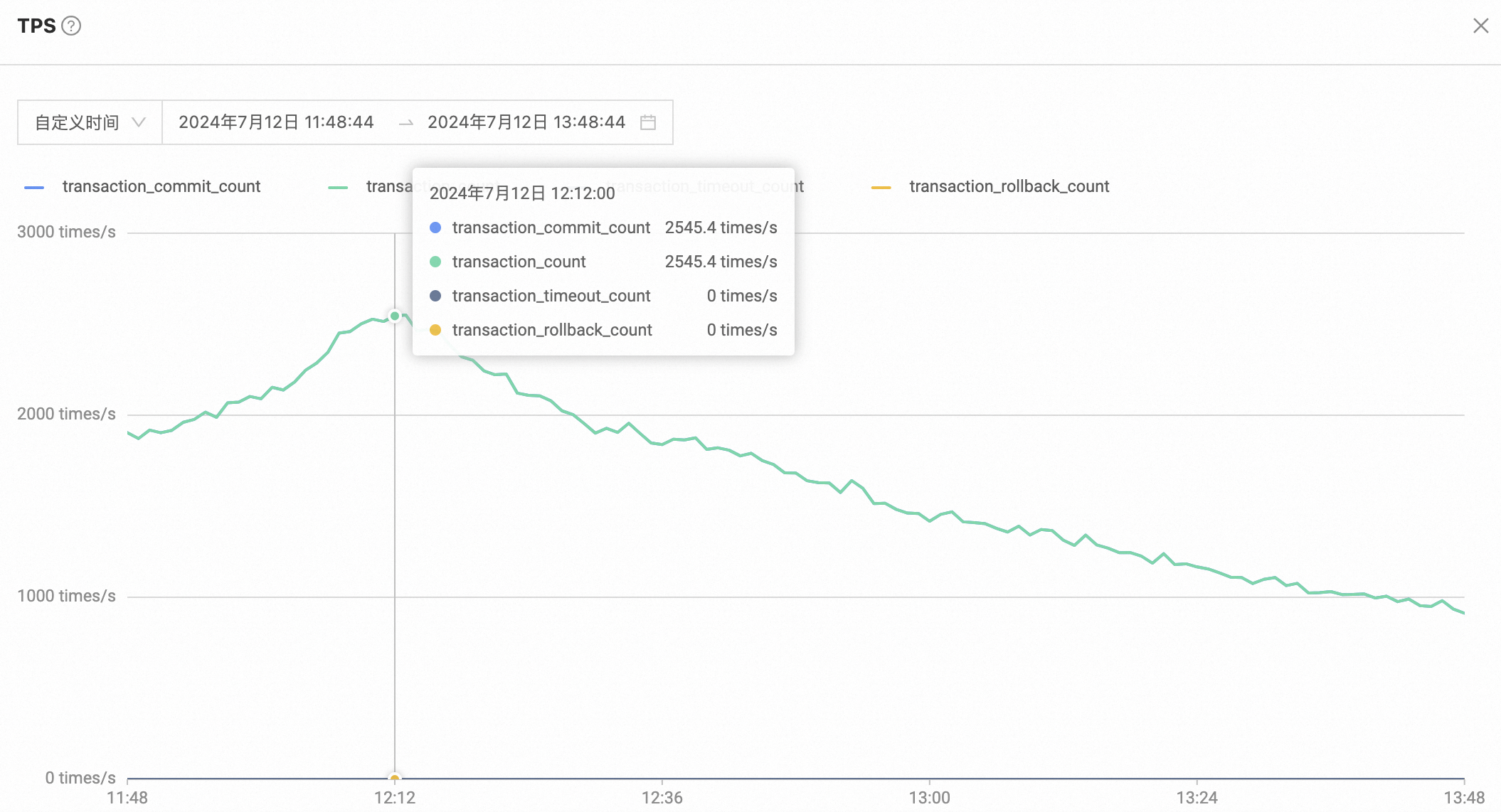
- 高峰期数据库QPS\TPS
2.2 数据库部署架构
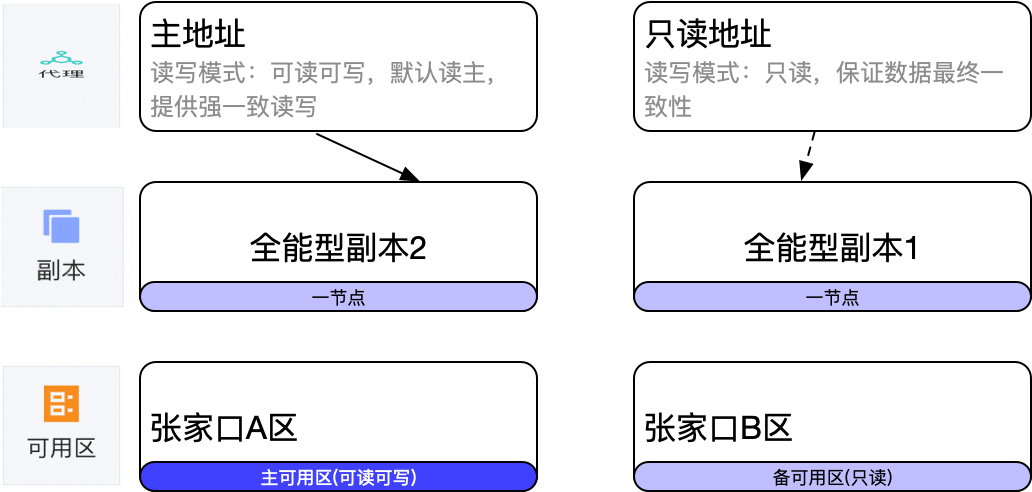
集群为双机房部署,分别在张家口A及B区,主可用区位于A区,提供可读可写能力,备可用区位于B区,仅提供查询能力;读写应用一般配置主地址,只读应用配置只读地址。
2.3 业务查询性能
智享版报表库70%的流量还是业务写,QPS和TPS都比较高,少部分商户查询都是AP场景。点查基本上没有问题,对于范围查询一般会查询一天、一周、一月的数据,通常一周内的数据查询没有性能问题,对于大KA查询一月的数据就会比较慢,通常要5-10s。
2.4 OB 3.2 目前存在的问题
- 部分SQL执行计划走偏
- 大表索引变更速度非常慢
3 技术目标
3.1 性能方面
目前最大查询时间周期为一个月,并且在1000家门店内耗时5秒以内,我们的目标是将查询时间缩短至2秒以内。
3.2 稳定性方面
目前我们使用的单台顶配104核CPU的服务器,其最高使用率为50%左右。即使商户数量翻倍,我们希望数据库的CPU使用率也不超过65%。
4 为什么选择分区化改造
当前智享版报表的存储层现状是Oceanbase 1:1:1 104核600GB,最大的表已经超过300GB,都是单表。
分区化改造的目的是为了提高查询性能,并且能够更好地支撑大型KA商户的需求。以下是为何要进行分区化改造的原因:
4.1 提升查询效率
对于单表查询来说,随着数据量的增加,查询的性能可能会下降。而通过分区化改造,可以将数据分散存储在多个分区中,每个分区只包含部分数据,从而减小查询的数据量,提高查询效率。
4.2 优化资源利用
分区化改造可以将数据分布在多个分区中,使得查询可以在分区级别上进行并行处理,从而充分利用多核CPU和其他硬件资源,提高系统的整体性能。
4.3 支持增量数据处理
对于大型KA商户,数据的更新频率可能很高,而分区化改造可以支持增量数据的处理。通过将数据按照时间或其他规则进行分区,可以方便地实现增量数据的导入和查询,减少全表扫描的开销。
4.4 优化维护和备份
分区化改造可以将数据按照逻辑或物理上的规则进行分区,使得维护和备份变得更加灵活和高效。例如,可以对热点数据进行单独的维护和备份,而对于历史数据可以进行压缩存储或归档,从而节省存储空间和维护成本。同时分区化改造后对于大表DDL速度也能明显提升30%以上。
综上所述,通过对门店进行分区化改造,可以提升查询性能,优化资源利用,支持增量数据处理,以及优化维护和备份。这样可以更好地满足大型KA商户的需求,并提升系统的整体性能和稳定性。
5 技术术语
| 术语 | 含义 |
| 分区 | 分区是将数据库的表或者索引按照某种规则拆分成多个部分,每一个部分被称为一个分区。这些分区可以独立存储和管理,从而提升数据库的性能和可扩展性。 |
| 副本 | 副本指的是数据库的一个完全拷贝。OceanBase通过在不同节点上存储数据的多个副本来实现数据的冗余和高可用。在一个分布式数据库系统中,每个分区的数据通常会维护多个副本,这些副本分布在不同的物理节点上 |
| Zone(可用区) | Zone 在 OceanBase 中指的是一个逻辑上的地理区或数据中心。每个Zone由多个Server(服务器)组成,这些服务器上运行着OceanBase数据库实例。一个OceanBase集群可以包含多个Zone,以实现高可用性和跨数据中心灾备。 |
| unit | Unit是OceanBase中的一个逻辑概念,它表示在OceanBase集群中的资源分配单元。每一个Unit包含一组资源,这些资源包括CPU、内存、磁盘等。OceanBase通过对Unit的管理和调度,实现了资源的弹性调度、负载均衡和高可用性。 |
| 转储 | 以“租户+observer”为维度,只是MemTable的物化,每个 MemStore独立触发冻结 。 |
| 合并 | 集群级行为,产生一个全局快照,所有observer上所有租户的 MemStore统一冻结。 |
更多术语请访问:https://www.oceanbase.com/docs/enterprise-oceanbase-database-cn-10000000000943758
二 方案选择
1 部署方案选择
部署方案通常有三种,多机房部署、双机房部署、单机房部署
1.1 多机房部署
云数据库 OceanBase 多机房部署指将三个节点部署在三个不同可用区,实现跨可用区容灾。
每个节点均为全能型副本,其中一个主副本提供读写服务,两个备副本提供只读服务。当主副本发生故障时,备副本将会升为主副本继续提供读写服务。
对性能和多机房可用性有着更高要求的客户建议选择多机房部署方案。
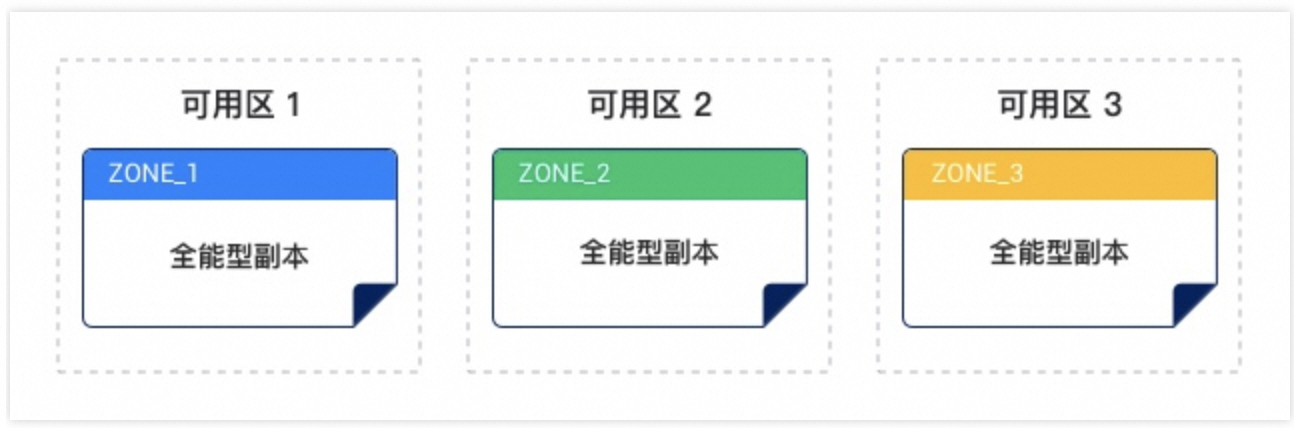
1.2 双机房部署
云数据库 OceanBase 双机房部署:
- 将两个节点部署在两个可用区,其中一个节点作为主副本提供读写服务,另外一个备节点可以提供只读服务。
- 在第三个可用区部署一个日志节点,该节点仅用于日志同步,不包含数据副本,不对外提供读写服务,并且日志节点对用户不可见。
双机房部署仍具备机房级容灾能力,与多机房部署相比在性价比上有较大提升。
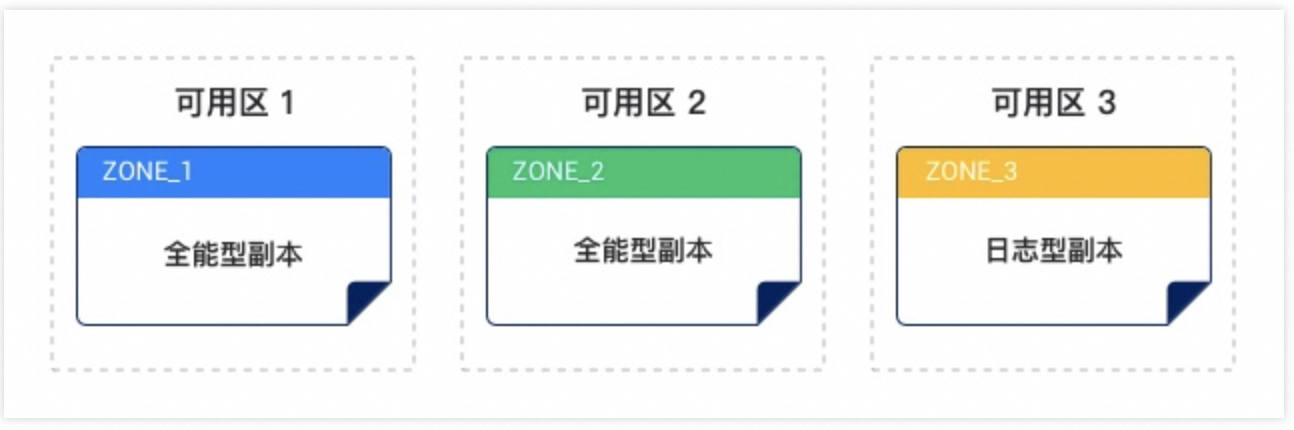
1.3 单机房部署
云数据库 OceanBase 单机房部署将所有节点位于同一可用区,具备主机级别故障容灾能力。
此外单机房部署还具备如下优点:
- 两个全能型副本同时提供读写能力,为您提供更高性能的数据库读写服务。
- 单机房部署的写请求无需进行跨机房同步,同机房内写请求的数据同步可以降低时延。
单机房部署的日志节点对用户不可见。

1.4 三种部署方案的区别
| 部署方案 | 多机房 | 双机房 | 单机房 |
| 节点个数(购买) | 3 | 3 | 3 |
| 全能型副本数 | 3 | 2 | 2/3 |
| 日志副本数 | 0 | 1 | 1/0 |
| 节点个数(用户可见) | 3 | 2 | 2 |
| 费用 | 购买配置*3 | 购买配置*2+购买配置*0.5 | 购买配置*2+购买配置*0.5 |
说明:双机房(2F1L) 副本方案中的日志副本对用户不可见,因此购买了 3 节点,实际上系统中仅 2 个节点可见。
2 节点分布选择
节点分布一般是1-1-1、2-2-2、3-3-3,总节点数一般是3的倍数
结合上一节的知识,如果节点分布是1-1-1,那么服务器数量就为3台,2-2-2服务器数量为6台,3-3-3为9台
上文中讲到客如云智享版报表当前的部署方案是双机房1-1-1,单节点配置为104C600G,高峰期主节点CPU使用率为43%
那么接下来新的分区集群需要综合考虑负载、性能、存储、成本、扩展性等方面因素来选择适合的部署方案及节点分布,初期可选的方案主要是如下二种,
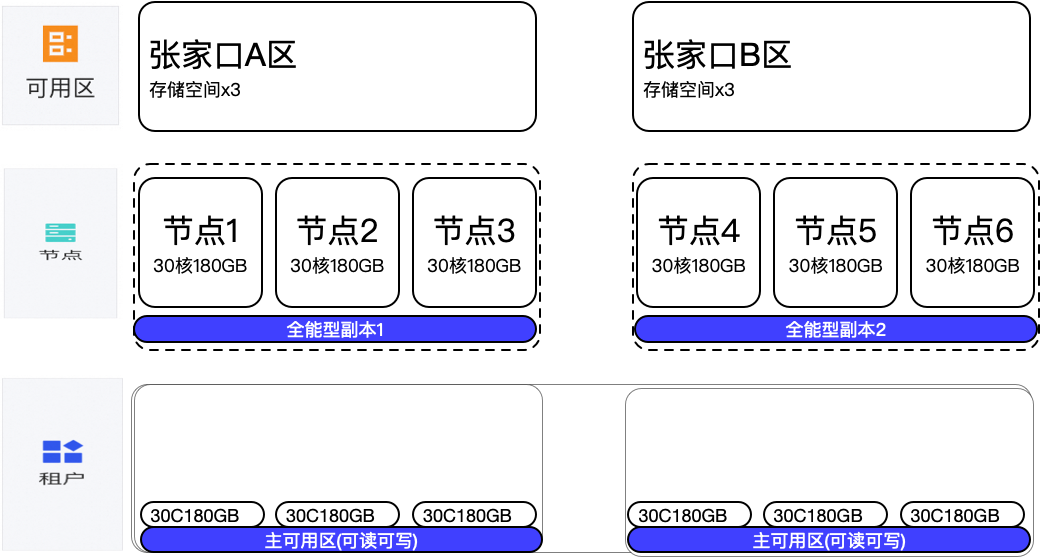
2.1 3-3-3 双机房 30C180G
双机房(可用区)部署,每个可用区3台机器,单台机器是30C180GB,总共9个节点,主可用区位于A、B 二个可用区,C可用区为日志型副本
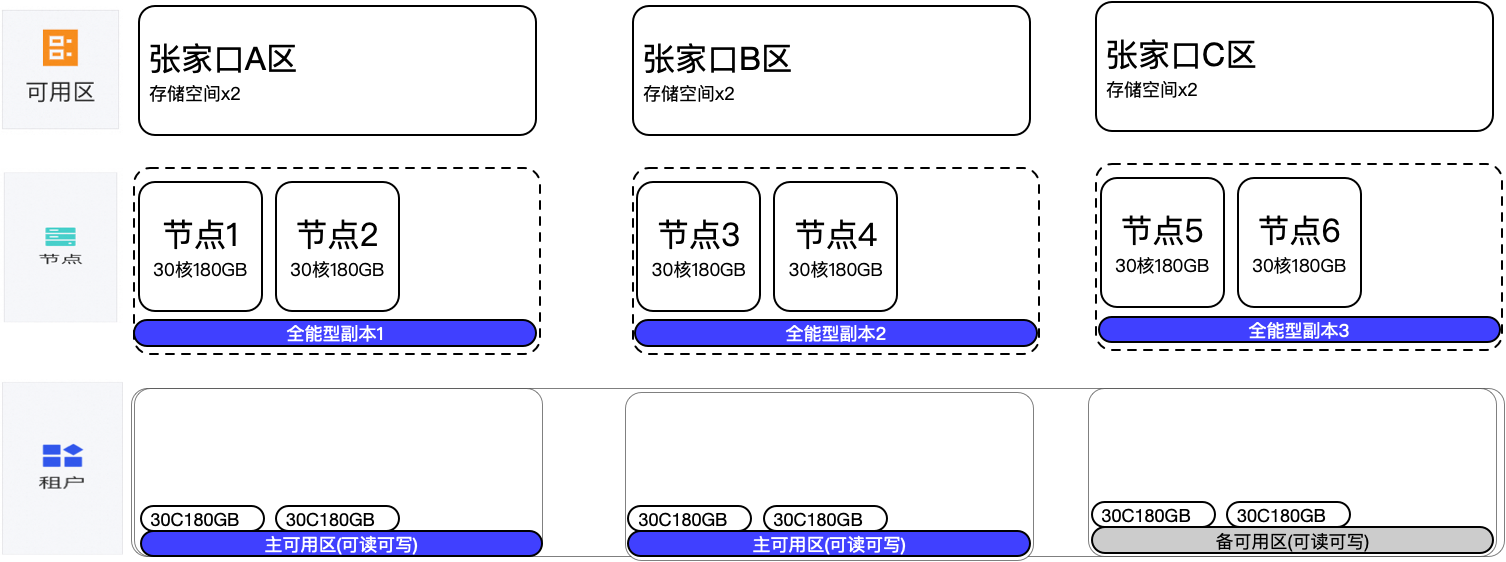
2.3 2-2-2 多机房 30C180G
三机房(可用区)部署,每个可用区2台机器,单台机器是30C180GB,总共6个节点,主可用区位于A、B二个可用区,A、B、C都为全能型副本
3 主可用区选择
主可用区一般有三种选择:
3.1 主可用区分布在3个可用区
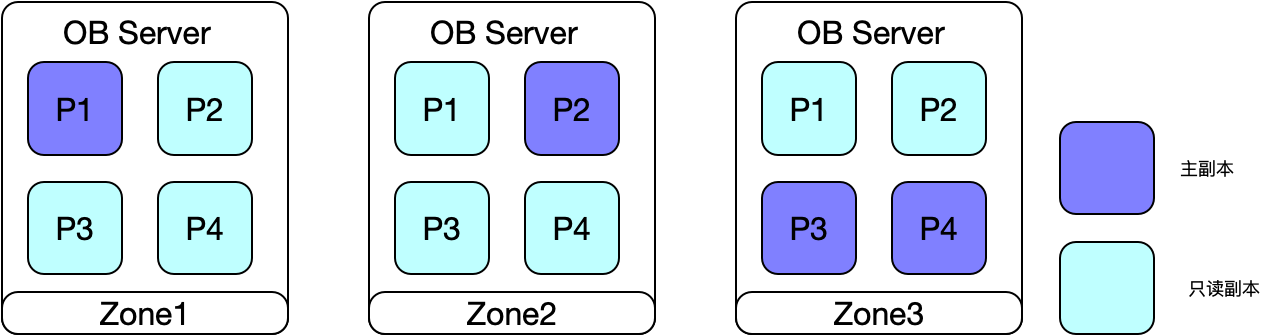
主副本均匀分布在所有机器上,适合批处理场景,希望尽快跑完,不关注某一个SQL的执行时间,期望让整体任务尽快完成。
3.2 主可用区分布在2个可用区
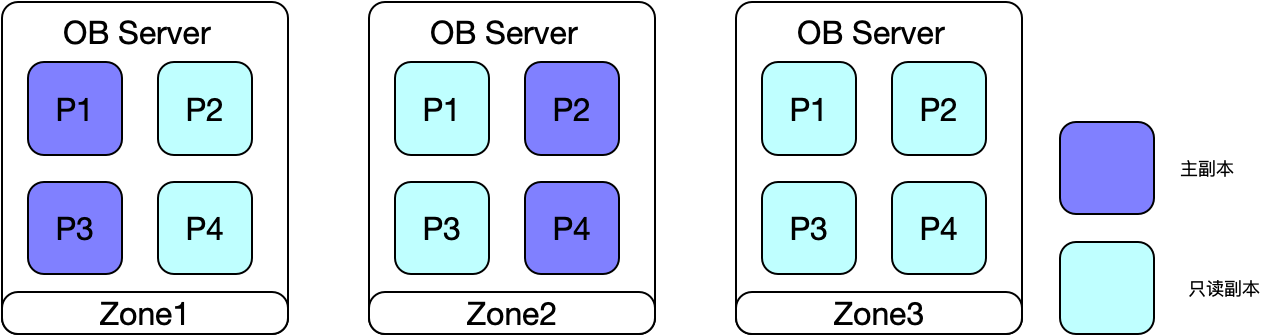
主副本均匀分布到Zone1和Zone2,Zone3均是从副本,适合城市容灾方案,将业务汇聚到距离较近的城市,距离较远的城市只承担从副本的角色(只读)。
3.3 主可用区分布在1个可用区
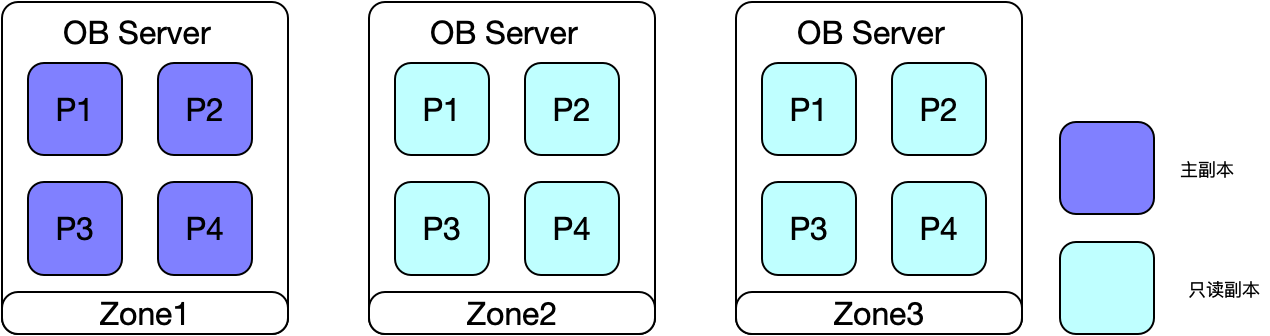
主副本只在Zone1存在,Zone2和Zone3均是从副本只读,适合对延迟敏感的业务,业务量不大,不超过一台机器的处理能力,可以尽量避免跨服务器访问,从而降低时延。
最终智享版报表选择了折中方案,将主可用区分布在了2个可用区,由4台30C的机器来承担写入。
4 分区数选择
选择分区数时需要考虑多方面的因素:
4.1 数据量
大型表通常需要分区以提升管理和查询性能。如果你预计表将存储大量数据,更多的分区可以帮助减少单个分区的大小,提升查询响应速度和数据管理效率。不过,太多的分区也可能增加管理的复杂性和开销。
4.2 数据增长
评估数据随时间的增长情况。如果数据量将迅速增长,规划更多的分区可以为未来的数据增长留出空间,减少以后重新分区的需要。通常可根据2-3年的业务数据增长量来评估机器数量,进而来定义分区数量。
4.3 查询模式
考虑应用程序主要的查询模式和使用的分区键。如果查询通常在特定的分区键范围内进行,优化这些分区的数量和大小可以提高性能。
4.4 资源利用与性能
分区可以帮助更有效地使用服务器资源,例如,CPU和IO操作可以在多个分区间并行执行。需要考虑服务器的资源情况和应用程序的性能需求,以选择合适的分区数。
5 分区键选择
在Oceanbase系统中,选择合适的分区键至关重要,可以大幅度影响整个数据库表的性能和扩展性。下面是选择分区键时应考虑的一些关键因素:
5.1 查询性能
分区键应该根据最常见的查询方式来选择。如果某个键经常用于WHERE从句中,那么使用这个键作为分区键可以提升查询性能。
5.2 数据分布
选择能够均匀分布数据的分区键可以避免数据热点,并最大化分区间的负载平衡。
5.3 数据增长
分区键也可以基于数据增长的模式选择,例如,如果数据增长是顺序的,则时间戳或某种顺序递增的键可能是一个好选择。
5.4 维护性和扩展性
使用分区键可以简化数据管理,例如数据归档和清理。另外,分区键选择应当支持未来的表水平扩展。
5.5 业务逻辑
分区键通常与业务逻辑紧密相关,如业务线、地区、用户ID等,这样能够更高效地实现针对特定业务的操作。
5.6 写操作
如果系统存在大量的写操作,则选择可以均匀分配这些操作的分区键,以优化写入性能并减少单个分区上的写入压力。
5.7 事务和并发
分区可以增加数据库的并发度,所以在预期较高并发量的表上使用合适的分区键,可以有效减轻锁竞争。
具体选择哪个列作为分区键没有硬性规定,它依赖于你的具体应用场景。但是通常情况下,以下列可能是不错的分区键候选:
- 时间戳或日期字段:对于日志或历史数据,时间是一个自然的分区维度。这也方便数据归档和分片。
- 业务属性:如客户ID、地区代码或者产品种类等,可以根据业务需求进行数据的快速访问和维护。
- 唯一属性:UUID、用户ID等在数据库中能均匀分布的唯一标识。
在选择分区键后,应该对其进行测试以验证是否能达到预期的性能和扩展目标。可以通过对比测试不同的分区键对查询速度、写入吞吐量以及系统的管理维护等方面的影响来做出选择。
三 方案上线
1 参数调优
根据实际的业务场景进行参数适当调整,可降低CPU负载
| 参数名 | 含义 | 值 |
| parallel_servers_target | 并行线程数 | 512 |
| _enable_calc_cost_for_range | range代价模型开关 False为保持323版本一致 | False |
| _enable_in_range_optimization | 通过代价决定一个in谓词是否参数range抽取 | True |
| optimizer_index_cost_adj | 数据倾斜场景的索引优化 | 10 |
| _mini_merge_concurrency | mini L0转储 | 2 |
| minor_merge_concurrency | minor L1转储 | 4 |
| freeze_trigger_percentage | memstore触发转储的阈值 | 50 |
2 数据迁移
数据迁移使用OMS迁移工具,支持的源端数据库类型如下:
| 实例类型 | 简称 |
| RDS 实例 | RDS |
| PolarDB MySQL 实例 | PolarDB |
| VPC 内自建数据库 | VPC |
| 数据库网关(Database Gateway) | DG |
| 公网 IP 自建数据库 | 公网 |
| OceanBase 数据库 MySQL 租户 | OB_MySQL |
| OceanBase 数据库 Oracle 租户 | OB_Oracle |
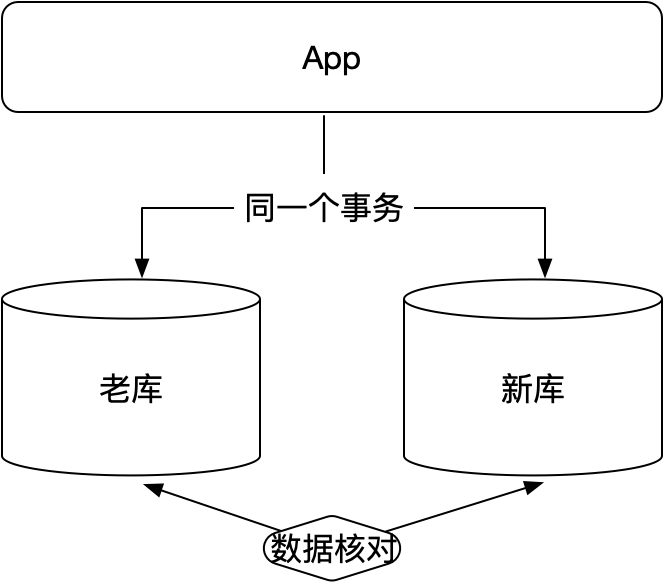
3 数据双写
为进一步保证业务的稳定性,满足三板斧要求,同时让整个切换过程更平滑,因此选择了数据双写。数据双写主要是通过应用层实现在数据库源库及目标库同时写入,通过事务来保持数据一致性,同时通过后台数据核对任务来保证数据库源端和目标端的数据一致性。
4 分阶段切换及回滚
整个上线切换包含多个阶段,主要包含预发查询切流、线上查询切流、预发写切流、线上写切流等
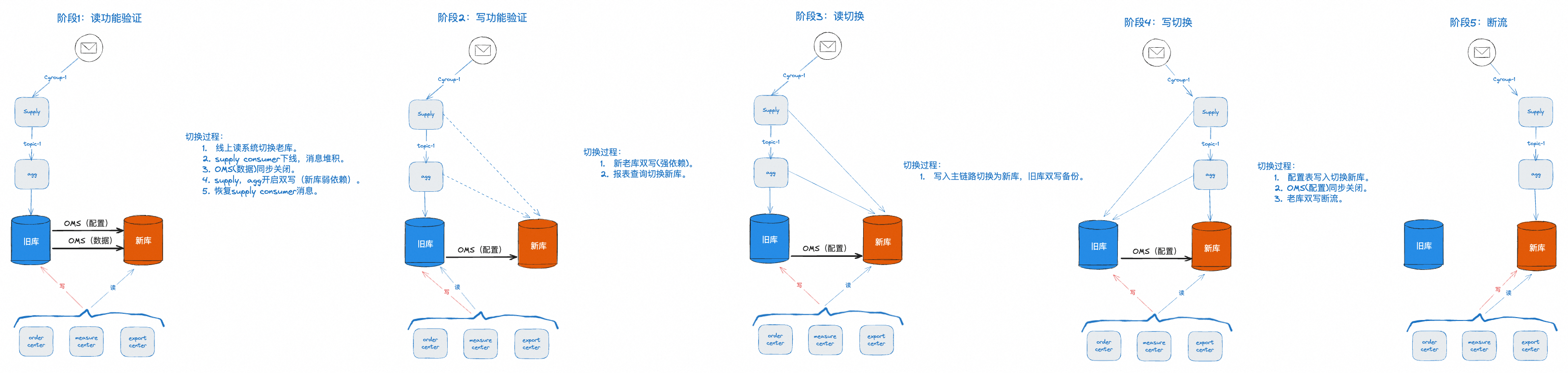
4.1 阶段1:业务读功能验证
新老库采用OMS数据同步工具保持实时同步(延迟为秒级),线上报表应用读数据切换到新库。如遇SQL问题可在1分钟内回切到老库(业务代码中已进行了SQL异常埋点,SQL问题可第一时间感知)
风险:低,可1分钟内回切老库,且可按机器灰度
4.2 阶段2:数据生产写功能验证
在阶段1的基础上,关闭OMS数据同步,线上报表读数据切换到老库,数据生产采用双写,验证新库数据写入性能和正确性。(写主链路在老库,新库为弱依赖,新库写入失败不会影响老库)
风险:低,可1分钟内新库写断流,新库写入失败不会影响老库,但双写会加重应用负载,需提前应用扩容
4.3 阶段3:业务读切换到新库
在阶段2的基础上,线上报表读数据分批切换到新库。老库不提供读
风险:低,可1分钟内查询回切老库,且可按机器灰度
4.4 阶段4:数据生产写切换到新库
在阶段3的基础上,写入主链路切换至新库,双写旧库备份(写主链路在新库,新库为强依赖,新库写入失败会影响老库)
风险:较高,老库只做备份用,新库写入或查询失败会影响业务,但支持5分钟内回切。
4.5 阶段5:老库断流
数据生产改为只写新库,旧库写入断流。
风险:最高,老库一旦断流后,无法再切回,新库有问题只能解决问题
四 收益
1 执行性能提升明显
汇总SQL耗时3.31s,改造前9.27s;多门店IN汇总耗时1.9s,改造前3.2s(第一次请求3.2,改造前9.2s)。
2 索引走偏问题明显好转
新分区库索引默认都是分区键+其他+时间的方式建Local索引,相比老库,新分区库执行计划走偏下降80%以上。
3 大表索引变更速度明显提升
分区表后,增加索引默认是分区并行执行,相比单表速度提升50%以上,但需注意对实例负载的影响。
五 遇到的问题
1 迁移数据时OMS增量阶段写入慢
业务中存在正常DELETE操作,OMS在解析SQL时会将一条SQL拆分为多条,导致增量阶段耗时比较久
2 SQL中不带分区键的情况
在老库中,SQL中没有强制要求必须带分区键,但是在新库中却是必须,通过SQL超时工具,及时发现SQL超时情况,推进业务解决
3 代码中指定了索引
由于OB中存在索引走偏的情况,在老库中部分查询场景SQL代码中指定了索引,因此在新分区实例尽量不更改索引名,否则可能导致全表扫描
4 自定义报表join问题
自定义报表使用了NESTED-LOOP JOIN,而在大表时执行速度会非常慢
使用了NESTED-LOOP JOIN,且索引走偏 ,解决办法:添加hint,/*+ use_hash(wide_promo wo)*/ 使用hash join
5 远程执行SQL较多
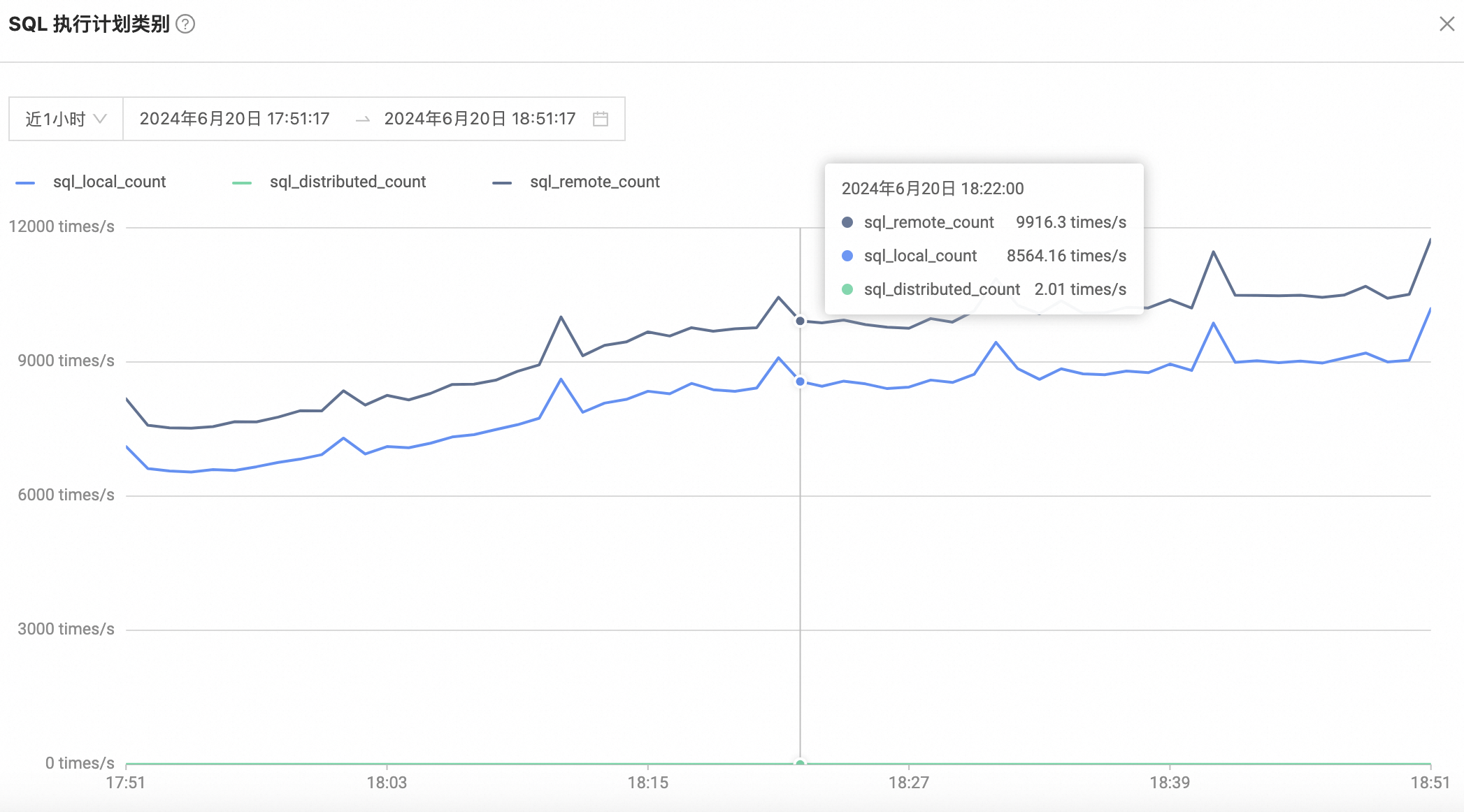
由于表都是按门店分区的,SQL中查询通常会指定品牌下多个门店,导致SQL执行需要路由到多个节点来执行,增加跨机开销(RT平均耗时为单机耗时三倍)
解决方案:增加表组,将一组表下同一分区主副本迁移到一个节点上,减少跨机执行,RT整体维持在单机执行同一级别。
六 后期扩容
1 水平扩容
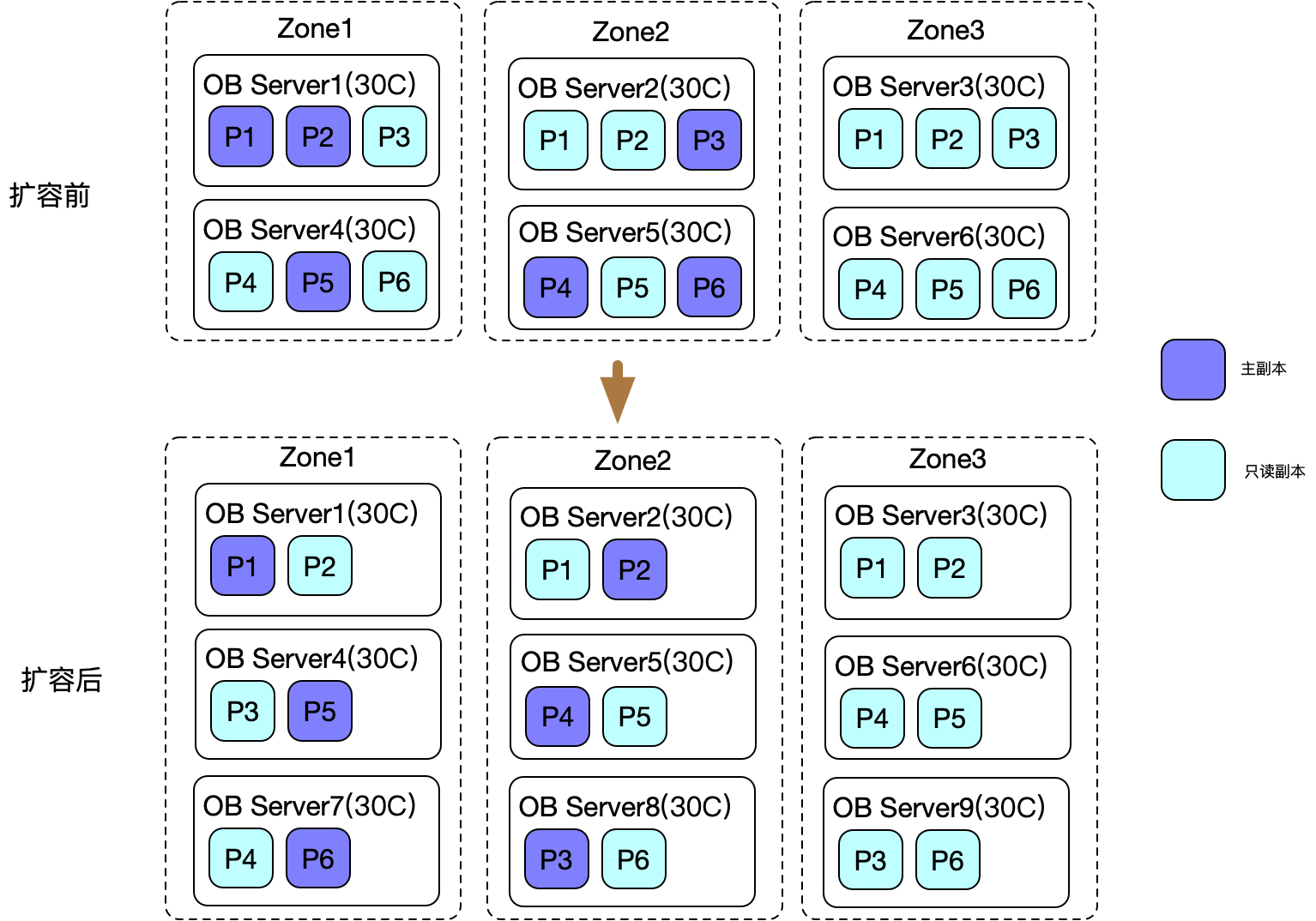
扩容基本步骤:
- 为每个Zone添加新的物理机器
- 在每台新添加的机器上启动observer服务
- 在每台新添加的机器上执行alter system add server命令,将observer服务添加到集群中
- 执行alter resource pool <pool name> unit num = <bigger number> 命令,扩充资源池中的unit个数
- OceanBase自动执行“rebalance”过程,将部分数据从旧的unit在线复制到新的unit上,此过程可能会花费一定时间,具体时间取决于数据量
- 每个分区的数据复制完成后,Oceanbase自动将服务切换到新的unit上,并删除旧unit中分区上的数据。
2 垂直扩容(节点规格升配)
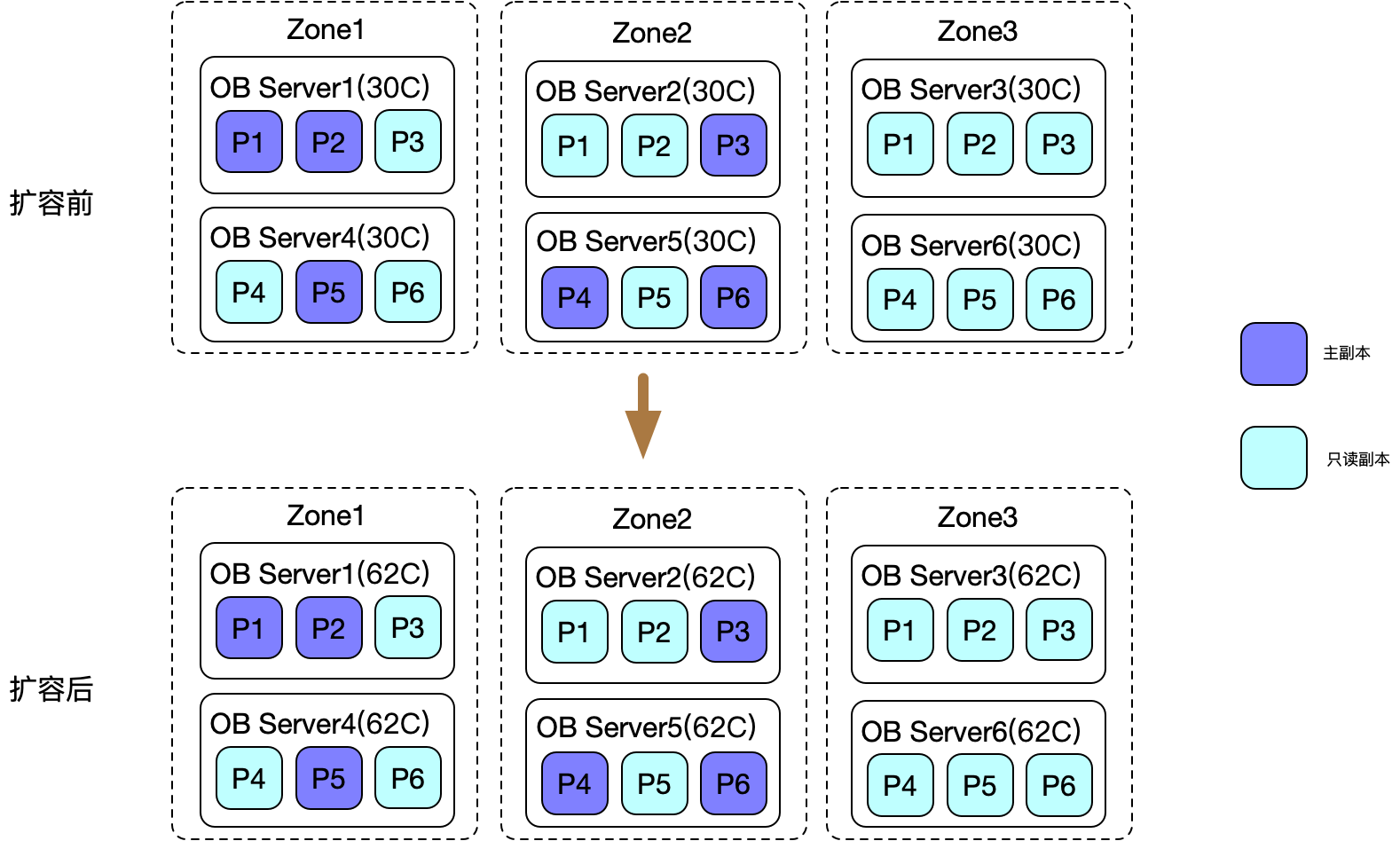
扩容基本步骤:
- 为每个Zone增加2台62C的物理机器
- 在每台新添加的机器上启动observer服务
- 在每台新添加的机器上执行alter system add server命令,将observer服务添加到集群中
- 迁移unit到新的机器上,迁移完成后直接替换老的机器(一个zone一个zone操作,中间会有切主动作,在执行迁移任务的节点不会有主副本提供服务)
3 主可用区打散
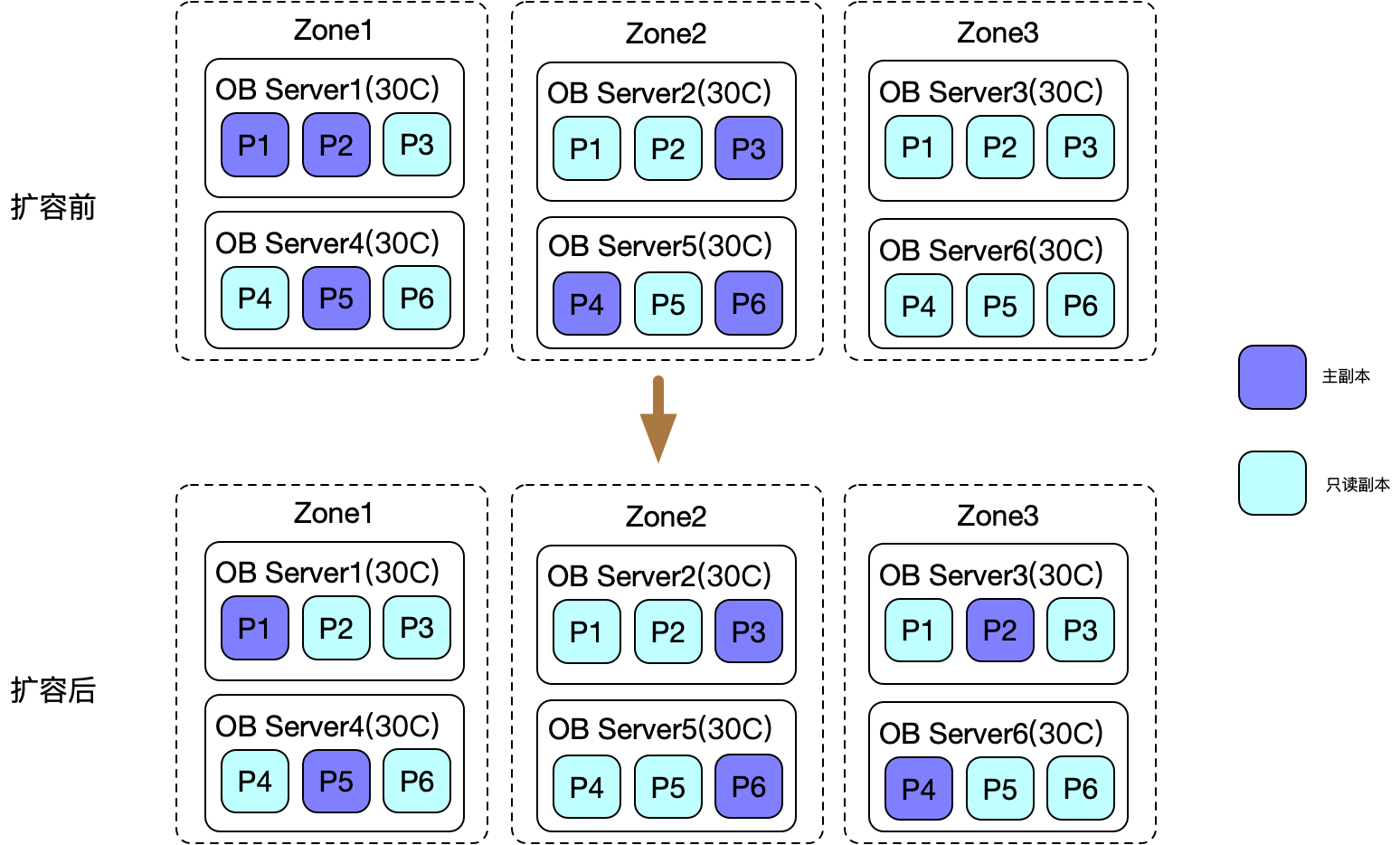
扩容基本步骤:
- 执行命令将主可用区分布到三个zone(zone1,zone2,zone3),ALTER TENANT <tenant name> primary_zone='zone1,zone2,zone3';
- OceanBase自动执行“rebalance”过程,将主副本迁移到三个Zone(可以阿里云控制台白屏操作,例:原主可用区位AB两个可用区,现将主可用区打散到ABC三个可用区,会根据均衡规则将AB可用区上的部分主副本切到C可用区,对于需要切主的这部分副本会有瞬时的抖动)
4 对比
| 扩容方式 | 耗时 | 机器数量 | 成本 | 风险 |
| 水平扩容 | 1-2小时 | 3 | 3台30C机器 | 无 |
| 垂直扩容 | 4-6小时 | 0 | 6台30C机器 | 无 |
| 主可用区打散 | 1-5分钟 | 0 | 无 | 只读查询流量可能影响到主可用区负载,跟OB确认,只读地址是随机路由到主从副本(只读Zone优先),可能进一步增加跨机分布式事务,建议设置table group |
七 总结
随着分区化改造的上线,智享版报表的大部分查询性能问题得到了有效缓解。分区化集群提供了持续的线性扩展方案,能够满足未来3-5年内业务快速增长的需求。然而,目前仍有部分大客户的查询需求无法完全满足。因此,未来我们需要继续优化,并在OB4.x的主要版本及业务层面上探索更多的创新与成果。

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐
 12
12 0
0- 0



 已为社区贡献772条内容
已为社区贡献772条内容

所有评论(0)