
百丽时尚DBA的分享:加入obdiag SIG,让OceanBase的运维更顺畅
本文分享一位DBA 在 obdiag SIG 的经验,以及如何通过这一身份更有效地解决OceanBase 生产环境中的遇到的问题
本文来自 百丽时尚 DBA的分享。
在百丽时尚应用OceanBase的过程中,我兼具双重身份:一方面,我是奋战在一线的DBA;另一方面,我也是OceanBase 敏捷诊断工具 obdiag特别兴趣小组(后简称 obdiag SIG)的成员,参与到该工具的共建研发。这里分享我在 obdiag SIG 的经验,以及如何通过这一身份更有效地解决生产环境中的遇到的问题。
obdiag 在百丽的应用
百丽时尚集团是中国一家大型时尚鞋服集团,从商品趋势研究,到设计研发,零售,再到客户运营,每个阶段都运用数字化技术。此前业务系统使用MySQL+MyCAT的分库分表架构,并使用orchestrator作为高可用的管理中间件。由于MyCAT架构下存在不支持分布式事务、分片业务调整困难和可扩展性差等问题,在2023将业务系统迁移至OceanBase4.2.1版本。OceanBase在分布式事务,分布式查询优化、水平可扩展性和周边工具生态方面表现优异,能够精准解决百丽之前的痛点并且减少运维难度和成本。自上线以来,在内部受到欢迎,目前已在订单中心和消息中心这两个核心业务中应用。
在日常的工作中,我们在信息收集、集群巡检、SQL诊断和问题根因分析等多个场景中都使用到了OceanBase的诊断工具obdiag。
obdiag是一款适用于黑屏的诊断工具,现有功能包含了对于OceanBase日志、SQL Audit以及OceanBase进程堆栈等信息进行的扫描、收集,可以在OceanBase集群不同的部署模式下(OCP,OBD或用户根据文档手工部署)实现一键执行,完成诊断信息的获取。obdiag帮助我们省略了此前遇到问题寻求官方支持时繁琐的信息收集动作,也加快了问题诊断的效率。
我眼中的 obdiag
作为obdiag的使用者和共建者,下面我从两个视角阐述obdiag带给我的收获,以及如何更好地利用obdiag 解决问题。
运维者视角的obdiag
站在运维视角,我们是这样使用obdiag的。首先以典型的实时锁冲突场景为例,下面有两个会话,它们都是做同一操作,即对一张表的一条数据做select for update操作。我们在会话一先执行,当会话二在做相同动作时就会等待。
面对上述场景,我们只需使用obdiag执行一条命令:obdiag rca run --scene=lock_conflict,即可一键分析出我们持有的会话及其事务ID,接着自动给出解决建议。
cat obdiag_lock_conflict_20240808175840/record
+------------------------------------------------------------------------------------------------------------------------------------------+
| record |
+------+-----------------------------------------------------------------------------------------------------------------------------------+
| step | info |
+------+-----------------------------------------------------------------------------------------------------------------------------------+
| 1 | by select * from oceanbase.GV$OB_LOCKS where BLOCK=1; the len is 2 |
| 2 | get holding_lock trans_id:31794294 |
| 3 | get holding_lock_session_id:3222014434 |
| 4 | wait_lock_trans_id is 31794336 |
| 5 | get wait_lock_session_id:3222015259 |
| 6 | exec sql: SELECT * FROM oceanbase.gv$OB_SQL_AUDIT where SID="3222014434"; to get |
| | holding_lock_sql_info. |
| 7 | holding_lock_session_id: 3222014434; not find sql_info on gv$OB_SQL_AUDIT |
+------+-----------------------------------------------------------------------------------------------------------------------------------+
The suggest: holding_lock_session_id: 3222014434; wait_lock_session_id : 3222015259, sql_info: not find.
Lock conflicts can be ended by killing holding_lock_session_id or wait_lock_session_id其次,以典型的历史锁冲突场景为例。当发生锁冲突我们没来得及执行分析命令或当下不知道执行什么命令,希望找到历史锁冲突时,有两种方法。第一种方法是通过OCP,可能会发现响应时间远远大于执行时间。
第二种方式是通过GV$OB_SQL_AUDIT:命令,也可以看到响应时间。
QUERY_SQL:select * from config where config_name = 'test rule' for update;
REQUEST_TIME:1723187738073566
ELAPSED_TIME:4513197
NET_TIME:0
NET_WAIT_TIME:0
QUEUE_TIME:0
DECODE_TIME:0
GET_PLAN_TIME:103964
EXECUTE_TIME:43923
RETRY_CNT:3403如果响应时间大于执行时间,往往会有多次重复执行,那么,结合看重复次数就可以判断是否发生了锁冲突。
接下来我们使用obdiag收集日志:
obdiag gather log --from='2024-08-09 15:10:00' --to='2024-08-09 15:30:00' --grep="ret=-6004"从日志中筛选和锁冲突相关的错误代码,比如6003/6004/6005。从日志中找到代码。
[2024-08-0915:20:52.514054]WDIAG[STORAGE.TRANS]inner_lock_for_read(ob_tx_data_functor.cpp:290)[279073][T1006_TenantInf][T1005][YB420AFA0270-0006196BA9DFF148-0-0][lt=4][errcode=-6004]lock_for_readneedretry(ret=-6004,tx_data={tx_id:{txid:325843478},ref_cnt:1,state:"RUNNING",commit_version:{val:1723188052513540049,v:0},start_scn:{val:1723188052513540049,v:0},end_scn:{val:18446744073709551615,v:3}这些代码意味着集群中出现过历史锁冲突,如此便可以快速定位历史问题。
最后一个例子是obdiagSQL优化,假设test1和test2是结构完全相同的两张表,但test2的数据量远大于test1。连接条件为t1.c1=t2.c1:
create table test1 (c1 int primary key, c2 int, key t1_i1(c2) local) partition by hash(c1) partitions15;
create table test2 (c1 int primary key, c2 int, key t2_i1(c2) local) partition by hash(c1) partitions15;
explain select * from test1 t1, test2 t2 where t1.c1 = t2.c1 and t1.c2 > 1 and t1.c2 < 1000;
======================================================================
|
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)|
| ----------------------------------------------------------------------
|0 |PX COORDINATOR | |89 |484 |
|1 |└─EXCHANGE OUT DISTR |:EX10001 |89 |416 |
|2 | └─HASH JOIN | |89 |264 |
|3 | ├─EXCHANGE IN DISTR | |89 |172 |
|4 | │ └─EXCHANGE OUT DISTR (PKEY) |:EX10000 |89 |138 |
|5 | │ └─PX PARTITION ITERATOR | |89 |62 |
|6 | │ └─TABLE RANGE SCAN |t1(t1_i1)|89 |62 |
|7 | └─PX PARTITION ITERATOR | |100 |63 |
|8 | └─TABLE FULL SCAN |t2 |100 |63 |
====================================================================== |
在执行计划中,会对test2做全表扫描,但这不是我们想要的,这时,我们就可以通过obdiag命令去收集执行计划。
obdiag gather plan_monitor --trace_id=TRACE_ID --env="{db_connect='-h127.0.0.1 -P2881 -utest@test -p****** -Dtest'}"从收集结果中可以发现,test2的估行和吐行差距过大,统计信息有问题!
call dbms_stats.gather_table_stats('test', 'test2');通过obdiag重新统一信息,就可以解决问题。obdiag简单易用,帮助我们解决了很多问题,运维效率不断提升。因此,我也希望投入更多精力,为obdiag做一些贡献。
开发者视角的obdiag
我加入了OceanBase的敏捷诊断工具兴趣小组,即obdiagSIG,这是一个建设并推广obdiag工具及生态的开源小组,目标是打造一个集用户体验卓越、功能强大、社群活跃于一体的OceanBase诊断生态系统。
在参与共建的过程中,我发现了很多与用户运维视角不一样的东西。例如obdiag rca锁冲突场景,对于使用者而言,有时无法采集到导致锁冲突的会话ID,而在开发者视角,发现导致这个问题出现的根本原因在于,obdiag是通过gv$ob_lock的trans_id和gv$ob_transaction_participants关联获取tx_id,然后关联gv$ob_transaction_participants,但gv$ob_transaction_participants是集群视图会取到多条数据。而用户持有的会话只是连接到后端的一个Observer上,其他的会话ID显示为0,导致用户无法采集到相应结果。
优化逻辑也比较简单,就是快速编辑本地运行目录中根因分析相关的脚本文件:obdiag/rca/lock_conflict_scene.py。只需要加一个条件,就是说计算ID是不等于零的。然后把对应的数据查出来,这时用户想查询的会话ID就会显示。
优化后:
cat obdiag_lock_conflict_20240808175840/record
+------------------------------------------------------------------------------------------------------------------------------------------+
| record |
+------+-----------------------------------------------------------------------------------------------------------------------------------+
| step | info |
+------+-----------------------------------------------------------------------------------------------------------------------------------+
| 1 | by select * from oceanbase.GV$OB_LOCKS where BLOCK=1; the len is 2 |
| 2 | get holding_lock trans_id:31794294 |
| 3 | get holding_lock_session_id:0 |
| 4 | wait_lock_trans_id is 31794336 |
| 5 | get wait_lock_session_id:3222015259 |
| 6 | exec sql: SELECT * FROM oceanbase.gv$OB_SQL_AUDIT where SID="0"; to get |
| | holding_lock_sql_info. |
| 7 | holding_lock_session_id: 3222014434; not find sql_info on gv$OB_SQL_AUDIT |
+------+-----------------------------------------------------------------------------------------------------------------------------------+
The suggest: holding_lock_session_id: 0; wait_lock_session_id : 3222015259, sql_info: not find.
Lock conflicts can be ended by killing holding_lock_session_id or wait_lock_session_id
再比如obdiag display功能共建,此前我们在运维过程中需要用到大量的SQL及命令,这些SQL和命令管理起来非常麻烦,往往都会记录在自己的“小本本”上,需要用到的时候再去翻找对应命令,而经验不足的用户在方面可能会无从下手。
因此,我们借助OceanBase官方的能力,将常用的一些命令和SQL集成到obdiag中,只需要一条命令,快速响应并展示结果,降低运维的难度,让小白用户也能像老鸟一样在OceanBase的海洋中遨游。
obdiagSIG共建经验及感受
很多用户和最初的我一样,认为参与共建会不会耽误自己的本职工作,或者对研发能力要求很高,担心自己无法胜任会遭受打击。但其实,参与OceanBase的共建非常简单,比如我们增加一个场景,只需打开运行目录对应模块下的配置文件,根据规则和步骤创建即可。例如:
#展示场景增加
vi~/.obdiag/display/task/observer/demo.yaml:
info_en:"[test]"
info_cn:"[测试case]"
task:
-version:"[3.1.0,3.2.4]"
steps:
{steps_object}
-version:[4.2.0.0,4.3.0.0]
steps:
{steps_object}目前的一些成果展示如下:
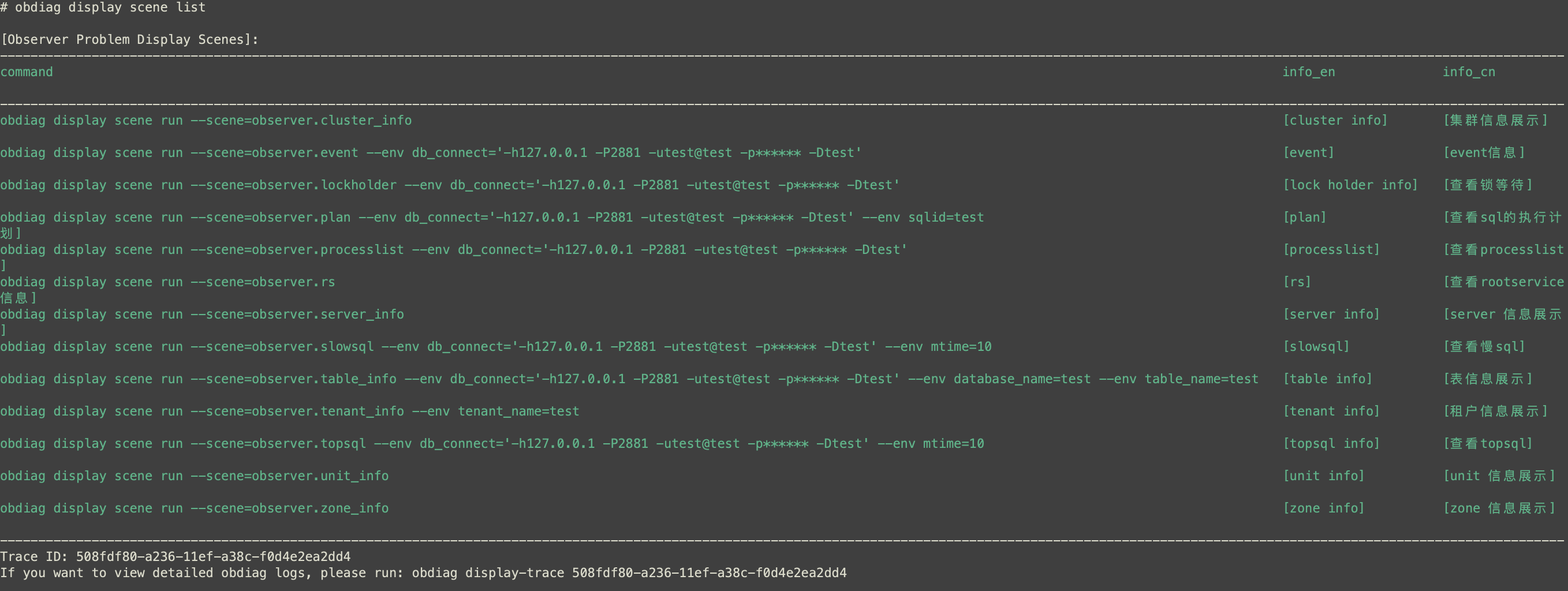
目前obdiag 2.5.0版本已经正式引入了obdiag display功能,也欢迎大家体验和给出指导建议。
加入obdiagSIG后,不仅没有耽误我的本职工作,还让我的运维工作更加顺利。这一切都源于自己在运维过程中,需要经常采集信息通过社区论坛等形式反馈给OceanBase官方,随着收集信息越来越多,收集频率越来越高,我开始接触obdiag。同时,我们利用obdiag解决生产问题的次数也越来越多,我开始对obdiag强大的DIY功能吸引,可以很便捷的把自己想要的功能植入obdiag,在共建的工程中也进一步加深了对obdiag的理解。
作为OceanBase的用户和obdiag的共建者,我真心希望更多的一线运维人员和开发者可以参与obdiag项目,集思广益,群策群力,建设更加完善的obdiag场景以及更加强大的obdiag知识库,更好地解决我们在运维过程中遇到的问题。感兴趣可以添加OB小助手(OBCE666),发送obdiagSIG入群即可加入。

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐

 28
28 0
0- 0



 已为社区贡献568条内容
已为社区贡献568条内容

所有评论(0)