
跨境电商OA系统,从MySQL到OceanBase的迁移与运维实践
作为一家跨境电商,目前已有数亿条的listing数据,随着数据量的激增,系统逐渐暴露出多种瓶颈与问题,因此开始考虑原有MySQL数据库的替换。经过选型落地为OceanBase,本文分享2次迁移的实践和运维经验。
本文来自 2024年OceanBase技术征文大赛——“让技术被看见 | OceanBase 布道师计划”的用户征文。也欢迎更多的技术爱好者参与征文,赢取万元大奖。和我们一起,用文字让代码跳动起来!
背景:跨境电商的数据图替换需求
我们是一家跨境电商,在国内进行商品开发,在国际电商平台上销售,当前在售SKU超过100万。因为管理的店铺众多,SKU信息扩展至各电商平台后,累积产生了数亿条的listing数据。
初期阶段,我们未实施数据库拆分策略,所有平台及店铺的数据表均集中在一个MySQL数据库中,且各业务间的关联查询未设任何限制。这一状况为后续的分库分表工作带来了极大挑战。目前,我们的总数据量已达6TB,涵盖1400多张表,其中单表最大记录数高达5亿,单表最大数据量则达到300GB。随着数据量的激增,系统逐渐暴露出多种瓶颈与问题,具体表现如下:
第一,在业务发展早期,我们使用的是MySQL单机,业务壮大后升级为集群,使系统中存在不少历史遗留的全表更新业务代码。一旦执行,MySQL主从延迟就会超过设定的阈值,导致从库无法使用。同时,所有SQL全部被路由到主库,导致主库CPU使用率飙升,进而使业务明显感知到卡顿。
第二,部分表,单表数据量太多,如果做一次整体业务调整,需要频繁更新整张表,容易出现TPS瓶颈。这时通常会进行分区,将TPS流量分片到不同机器,提高业务执行效率。结合业务来说,假设我们对商品做一次全量调价的操作,为了确保调价成功,会将调价信息发送到RabbitMQ。然后通过多台消费者进行接口调用并更新数据。但当出现大批量的调价需求时,如果增加过多消费者,会造成数据库压力过大。在维持日常业务使用的情况下,消费完整个队列的消息可能需要1-2个星期。这显然不符合业务预期。
第三,历史代码量太多,业务中使用的关联多表的查询较多,使用传统的分库分表方案,改造工作量巨大,而且不好处理跨机关联查询引起的性能问题。
第四,MySQL数据膨胀厉害,云盘存储费用高涨,亟需优化存储成本。
数据库选型及两次迁移实践
基于上述痛点,我们亟需一款新的数据库,且需要具备以下特点:
- 有优秀的分库分表架构能力。
- 集群整体高可用,主要是从库延迟低,能稳定提供读服务。
- 可以灵活扩展。
- 运维简单,便于查找实时问题SQL。
- 能降低存储成本。
在经过初步调研市面上排名前十的数据库(墨天轮排行),发现OceanBase技术架构强大,产品文档完善,当我们在社区求助时很快就能得到反馈和解答。最重要的是OceanBase的产品能力:
- 表组和复制表特性,能极大地减少分区带来的跨机关联查询消耗,非常有利于我们简化后续的表分区工作。
- 数据压缩率高,最开始了解到OceanBase数据压缩率为1:3,而在实际应用后发现MySQL 6TB的数据,同步到OceanBase只需要920GB的空间,压缩率达到惊人的1:6。我猜测是由于MySQL中存在大量由于数据删除而未释放的空间造成的。而在OceanBase的实际使用中,我们完全无需担心这一问题,因为每天OceanBase都将有一次数据合并,整理存储空间。
- 集群架构的高可用性和开源免费的OCP运维工具,比较适合自建集群运维,白屏页面化操作对于集群监控、集群扩展、SQL诊断能提供极大的方便。同时也省略了使用RDS时,需要花费的监控和SQL诊断服务费用。
- OceanBase使用的Paxos协议,虽然把写放大了,但从另一个维度降低了主从副本数据同步的延迟。低延迟对于我们原有的一主二从的RDS MySQL架构来说,更能发挥从副本机器的查询性能。
下面来具体讲一下我们的迁移过程。下表是我司最开始使用RDS的机器配置和成本。以及最终迁移完成后,使用的OceanBase机器配置和成本。
| 数据库版本 | 配置 | 架构 | 成本 |
| RDS MySQL8.0 | 52核512GB内存;每台云盘6TB | 一主二从 | 5年成本约126w |
| OceanBase 4.2.1-8BP | 64核512GB内存;每台云盘1.5TB | 1-1-1. 三个全能型副本 | 5年成本约76w |
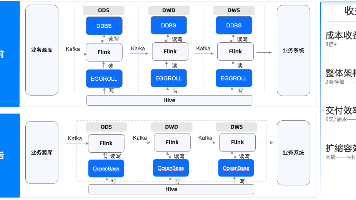
生产库从MySQL迁移到OceanBase ,我们做了两次尝试,在这里万幸OceanBase提供了专业的数据迁移工具OMS,支持数据的反向同步。正是这一功能顺利支撑了我们多次调整后的数据迁移。
第一次,为了尽可能提高整体写性能,根据RDS原配置的核数和内存。我们使用9台16核64GB的小型机部署OceanBase3-3-3的集群,将数据较多的表做分区。同时,将相同业务的表加入同一个表组,把多个业务需要关联查询的部分表,改成复制表,解决跨机查询带来的性能问题。这种方案完美的解决了业务高频次的TPS请求延迟问题。但由于我们过于急切地使用这种完美的切换方案,导致迁移的集群性能无法支撑原业务的日常请求。主要存在如下问题。
- 历史代码存量过多:虽然做了很长时间的准备(分区、分表组、改复制表、关联查询和DDL语句加分区键),但还是有“漏网之鱼”导致存在较多跨机关联查询,占用了大量CPU。
- 部分业务表无法分区:有些业务没办法分区而且请求量大,单台小型机完全无法支撑这部分业务请求,一个节点受阻就会使整体写同步延迟。
- 我们将OBProxy和OBServer部署在同一台机器上,当这台OBServer由于提供查询导致CPU使用率过高时,通过OBProxy请求会造成阻塞。
第二次迁移基于失败经验,我们意识到需要解决三个问题。第一,单机性能需要提高,最少要能hold住无法分区的业务量最大的模块的请求;第二,历史代码庞大,所有业务模块整体分区工作量太大,而我司也亟需尽快升级数据库架构;第三,OBProxy不能和OBServer部署在同一台机器。
经过优化,我们决定使用64核512GB内存部署OceanBase 1-1-1集群再次尝试,而且将迁移和改造分三个阶段进行。
第一阶段,将所有表加入一个大组,表结构暂时和MySQL一致,不做分区。这样就避免了跨机查询的问题。部署2台OBProxy,一台查询只使用主副本,另一台查询优先使用从副本,通过延迟阈值的多次调整,确定了400ms的延迟阈值。因为这个代理的查询请求几乎都会发送到从副本请求,而400ms的延迟对业务来说是可接受的(相较之下,MySQL延迟阈值3s,才能使用上一半从副本的性能)。同时为了避免由于主从数据不一致问题,我们对应用进行了改造,所有开启了事务的读请求,都会使用主副本查询。
第二阶段,分业务模块逐步改造业务分区和表组,检查所有关联查询代码以确保不会存在跨机关联。然后将整个模块的表进行分区,并从原来的大表组中迁移到新的业务模块表组中,逐步将主副本打散到所有机器上。
第三阶段,所有业务模块都完成分区和表组的改造后,取消读写分离代理。全部使用主副本查询数据,完全消弭掉同步延迟带来的数据不一致问题,为后续集群扩容做好准备。
OceanBase试运行收益
目前为止,OceanBase 已经在内部OA系统试运行一个月,总体来说,以OA系统目前的数据量来看,使用OceanBase 和此前用MySQL执行SQL的效率相近,后续随着数据量的增加,预计OceanBase的性能优势会逐渐显露。
另外,在上线一个月以来,我们已经明显感知到OceanBase带来的优势,简要总结为以下四点。
第一,存储成本下降40%,原MySQL单台机器需要6TB存储空间,在OceanBase单台机器只需要1.5TB,存储空间节约了3/4。
第二,由于OceanBase使用LSM Tree结构,优先写内存和日志,对于云盘的性能要求也下降了,云盘的性能级别从P2降为了P1。相较之下,原本在RDS需要使用L2级别10wIOPS性能的数据盘才能扛住的业务访问压力,OceanBase 使用L1级别5WIOPS的数据盘就足够支撑。
第三,主从延迟稳定性提高。由于OceanBase 主从延迟低,能保证从库性能使用率,进而提高了整个集群的系统稳定性及性能稳定性。目前为止,还没出现因为从副本延迟过高导致所有查询都打到主副本的情况,更没有整个服务卡顿或主从延迟导致主副本请求飙升的情况。
第四,运维效率提升,运维成本降低。OCP提供了全量SQL诊断,帮助我们更便捷地进行全局慢SQL监控。这在此前的RDS MySQL需要开启全量SQL才能实现,每天消耗几百块钱。可以说OCP帮我们省了一笔运维费用。
不过从MySQL迁移到OceanBase也还是有些不兼容的地方的。如下。
1. OceanBase 4.2.1版本暂不支持全文索引,OceanBase 4.2.3版本开始支持,但该版本暂未推出GA版本,所以我们本次迁移还是选择了4.2.1版本。
2. OceanBase 的SQL解释执行器效率没有MySQL高,对于传入参数较多的SQL,比如in查询范围较多的情况,获取执行计划就比较慢。
3. OceanBase 在部分SQL上,类型转换的优化不如MySQL完善,例如or查询中,条件中的字符串不会自动转换为int,导致无法使用索引。
4. OceanBase 4.2.1不支持临时表。
5. 同样的SQL,执行器每次给出的查询方案可能不同。通常是数据分布和索引创建异常。该问题也存在于MySQL中,例如查询时间范围内的数据,如果指定的时间所占整体数据的15%左右,就可能不使用这个时间字段的索引,引发全表扫描。如果要强制使用索引,需要指定force index,会有代码侵入。相比之下,OceanBase 给出了优化方案,我们可以通过告警知道哪些SQL波动导致恶化,然后绑定一个执行计划,相当于在数据库运维层面解决问题。
OceanBase运维经验
在使用OceanBase的过程中,我们也积累了一些经验,下面以问题及相应解决方法的形式进行分享。
问题1:使用读写分离代理访问时,即使开启了事务,查询也不会使用主副本,会造成数据一致性问题。
解决方法:对应用进行改造,对开启了事务的方法,指定使用主副本代理连接。 这对于所有刚刚从MySQL迁移到OceanBase,又需要从副本提供查询能力的用户来说,应该是一个通用的解决方案。
问题2:生产集群内存配置问题,一开始为了尽最大可能使用所有内存,我们直接指定了memory_limit=512G. 在夜间存在数据统计的大查询,导致内存溢出, 阿里云服务器直接消除了OBServer。
解决方法:一种方式是按照官方推荐,memory_limit改回默认值 0M. 默认常驻使用80%的机器内存。另一种方式是优化大查询,同时规范所有SQL书写,在以后需要更多内存的时候,将memory_limit改为90%。
问题3:夜间合并时,磁盘使用量突增20%,触发90%预警。 LSM Tree结构决定了每天需要合并数据以减少垃圾数据的存在。使用OceanBase 需要额外考虑多加20%的磁盘空间用于合并时的空间伸缩。
解决方法:额外扩容20%的磁盘。
问题4:数据备份设置了7天恢复期,但实际存储的备份量为14天。
解决方法:通过日志备份量和数据备份量分析,因为每天生成的日志备份量和整库备份使用的空间是差不多的,我们可以直接改为每天都全量备份,这样就能保持仅留存7天的备份数据了。
总体而言,OceanBase的应用符合预期,OB社区官方人员的及时响应和活跃的社区用户互帮互助,给了我们更大的信心。由于对新数据库的不够熟悉我们在使用过程中走了一点弯路。

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐

 17
17 0
0- 0



 已为社区贡献568条内容
已为社区贡献568条内容

所有评论(0)