
快速构建 RAG 新选择:FastGPT + OceanBase 向量检索
随着人工智能的快速发展,RAG(Retrieval-Augmented Generation,检索增强生成)技术日益受到关注。向量数据库作为 RAG 系统的核心基础设施,负责知识库的向量化存储与高效检索,堪称 RAG 的“记忆中枢”,其性能直接关系到大模型生成内容的精准度与实用价值。
FastGPT 是开源 的AI Agent 开发框架,集成了即开即用的数据处理和模型调用能力,用户可通过 Flow 可视化界面灵活配置工作流,轻松实现复杂场景的快速部署。
然而,随着应用规模的不断扩大、数据量的持续增长,以及更高维度的向量模型(如上千维的 Embedding)和更复杂的检索逻辑(如先按类别筛选再找相似内容)的出现,传统数据库在向量处理方面的局限性逐渐显现。
为了满足日益增长的高性能、高扩展性和高易用性需求,FastGPT 宣布正式上线 OceanBase!
OceanBase 作为一款高性能的分布式数据库,在向量功能方面展现出了显著优势,是 FastGPT 向量 Embedding 存储的更优选择。
向量数据处理之困:传统数据库在 RAG 中的瓶颈
在向量数据这种 “新物种” 面前,FastGPT 原本使用的某传统数据库在实际应用中暴露出三大核心问题,具体表现如下:
1、向量维度限制:“高维模型放不下”
当训练完成的高性能 Embedding 模型维度达到 2048 维或更高时,传统数据库的 HNSW 索引仅支持最高 2000 维的全精度存储。开发者若想使用高维模型,要么进行降维处理,而这将导致模型精度损失;要么面临无法存储的困境,限制模型优化空间。
2、混合检索的 “坑”:“我想精准找,怎么这么难?”
在实际业务场景中,RAG 系统需要在特定条件下进行向量检索。比如,仅在“技术文档” 类别中查找与“数据库优化” 相关的内容,这种 “先过滤、再搜索” 的需求,就是混合检索。
然而,某传统数据库的 HNSW 索引缺乏原生混合过滤能力,需要先通过 HNSW 召回大量向量,再于应用层或数据库层面进行二次过滤。这种处理方式不仅效率不佳,在数据删改频繁的情况下,旧数据 (死元组) 可能干扰 HNSW 的召回过程,导致过滤后关键数据丢失。
即便引入递归搜索进行优化,在实际测试中,仍存在查询性能下降、索引失效的情况,增加 SQL 编写复杂度,整体使用体验不佳。
3、VACUUM 的 “痛”:“空间回收跟不上”
某传统数据库依赖 VACUUM 机制回收数据删除或更新后产生的空余资源,适用于文本、数字等数据。但向量数据体量较大,单个向量可达到数 KB 以上。在大规模数据删改更新的场景下,某传统数据库的 VACUUM 处理效率跟不上数据更新的速度,导致数据库文件持续膨胀。开发者需要手动、频繁地执行 VACUUM FULL 操作,该过程会造成锁表,或者被迫给 Autovacuum 分配更多的系统资源,显著增加运维成本。
OceanBase 为 RAG 定制向量存储方案
面对上述挑战,OceanBase 凭借其分布式架构与创新技术,为 RAG 应用的向量数据库提供了更具竞争力的向量存储方案,在 FastGPT 项目升级中展现出显著优势:
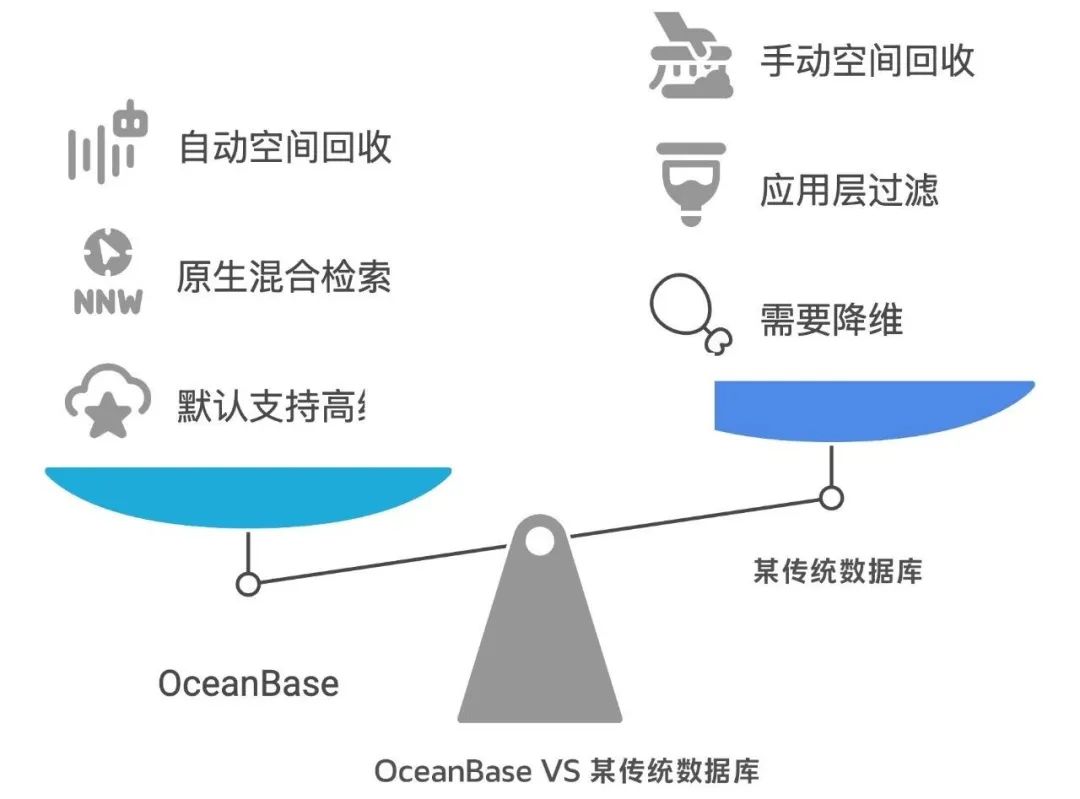
1、轻松驾驭 4096 维,还能更高!
OceanBase 的向量索引默认支持高达 4096 维的向量存储,且该维度的上限可以通过配置灵活扩展,最高支持 16000 维的 Float 类型的稠密向量。开发者可以放心地选用更高维度的模型来追求更好的效果,不用因为数据库限制而牺牲模型精度。
2、原生混合检索:精准、高效,一步到位!
OceanBase 的向量索引原生支持混合检索,可以直接在查询时就告诉它:“嘿,帮我在 ‘这个分类’ 并且 ‘那个标签’ 下,找和 ‘这个描述’ 最相似的向量”。OceanBase 可以在索引层面一边进行精确的标量过滤,一边进行高效的向量相似度搜索。这种优势显而易见:
👉 精准: 先框定范围再搜索,提高查询效率,避免数据丢失。
👉 高效: 索引层直接搜索,避免应用层二次过滤的开销,提升查询速度,避免索引失效,降低 SQL 开发难度。
3、空间回收更 “智能”:自动管理,省心省力!
OceanBase 基于与某传统数据库不同的 LSM-Tree 架构,拥有更完善、更自动化的空间回收机制,能高效处理向量数据的增删改操作,对于向量这种体积大、更新频繁的数据类型更加友好。
简单来说,开发者无需再为 VACUUM 维护投入大量精力,OceanBase 会在后台更平稳、高效地处理空间回收,减少了数据库膨胀的烦恼,也大大减轻了运维负担,让开发者能更专注于业务逻辑。
OceanBase 还有一些加分项:
单表多列索引支持:OceanBase 支持在单表中对多个不同的向量列 (比如标题向量、内容向量) 建立索引,满足复杂业务场景需求。
分布式弹性扩展: OceanBase 作为原生分布式数据库,在高并发、大数据量的场景下具备水平扩展能力与高可用性。虽然 FastGPT 暂时规模不大,但 OceanBase 可适应业务规模动态增长。
国产适配能力: OceanBase 可为有国产适配需求的项目提供专业可靠的技术支撑。
综上所述,选择 OceanBase 作为 RAG 应用的向量数据库,能让开发者拥抱更高维模型、实现精准高效混合检索、摆脱繁琐的 VACUUM 维护,显著提升 RAG 应用的性能、功能和易用性。
实战部署:基于 OceanBase 快速构建 FastGPT
准备工作:
📜 注册并获取 Sealos Cloud 账号权限。
📜 熟悉 OceanBase 的基本部署概念,确认目标 OceanBase Docker 镜像版本。官方文档地址:
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000002013494
步骤一:在 Sealos Cloud 控制台创建应用
登录 Sealos Cloud (sealos.run),进入 Sealos Cloud 控制台后,导航至 “应用管理” 或 “应用启动台” 功能模块,点击 “新建应用” 或 “创建无状态服务” 按钮,开始配置新的应用部署。
步骤二:配置应用基本信息与网络
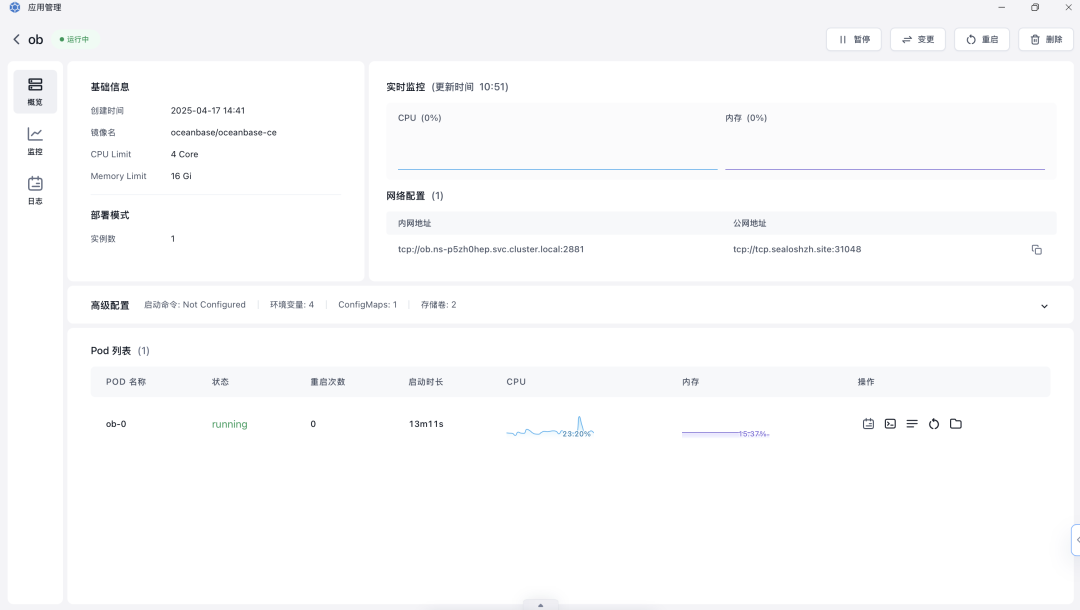
参考如图所示界面,进行如下配置:
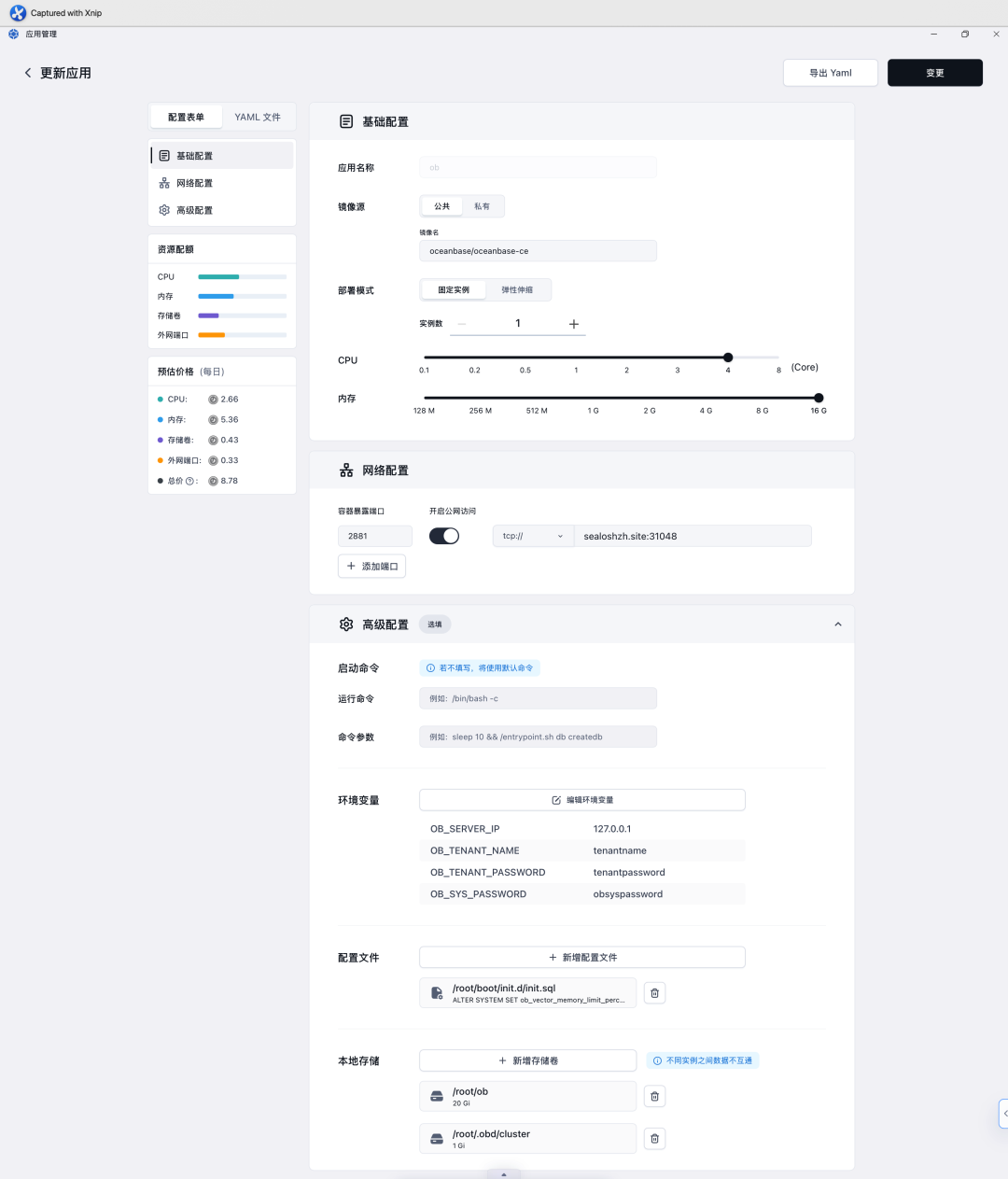
🔎 容器镜像 (Image Name):输入 OceanBase 数据库 Docker 镜像名称。请确保镜像是官方或可靠来源提供的,并注明版本(例如 oceanbase/oceanbase-ce)。
🔎 应用名称 (App Name):为 OceanBase 部署设置一个易于识别的名称。
🔎 计算资源 (CPU/内存):根据 OceanBase 的资源需求和使用场景,配置合适的 CPU 和内存资源。
🔎 网络配置 (Network Configuration):开启 TCP 协议端口暴露。点击 “添加端口”,容器端口 (Container Port) 设置为 OceanBase 数据库默认监听的服务端口,通常是 2881。设置对应的服务端口 (Service Port) 并选择适当的 暴露方式 (Exposure Method)(例如选择公网暴露,以便外部客户端连接到您的数据库)。
步骤三:配置环境变量
在 “高级设置” 或 “环境变量” 区域,根据 OceanBase Docker 镜像的官方文档,添加启动和配置 OceanBase 实例所需的环境变量。例如:
💡 OB_SERVER_IP: OceanBase 节点的服务 IP 地址。
💡 OB_TENANT_NAME: 要创建或连接的租户名称。
💡 OB_TENANT_PASSWORD: 租户的密码。
💡 OB_SYS_PASSWORD: SYS 租户的密码(用于管理)。
步骤四:配置持久化存储
🔑 数据库的数据、日志等核心文件需要持久化存储,以防止容器重启或删除导致数据丢失。
🔑 在 “本地存储” 或 “持久化存储” 区域,参考下图所示的挂载配置,为 OceanBase 容器挂载持久化存储卷。
🔑 点击 “添加存储卷”,选择或创建一个存储卷,并将其挂载到 OceanBase 容器内部存放数据、日志和配置文件的关键路径。请务必查阅 OceanBase 镜像的官方文档,确认需要挂载哪些具体的路径。
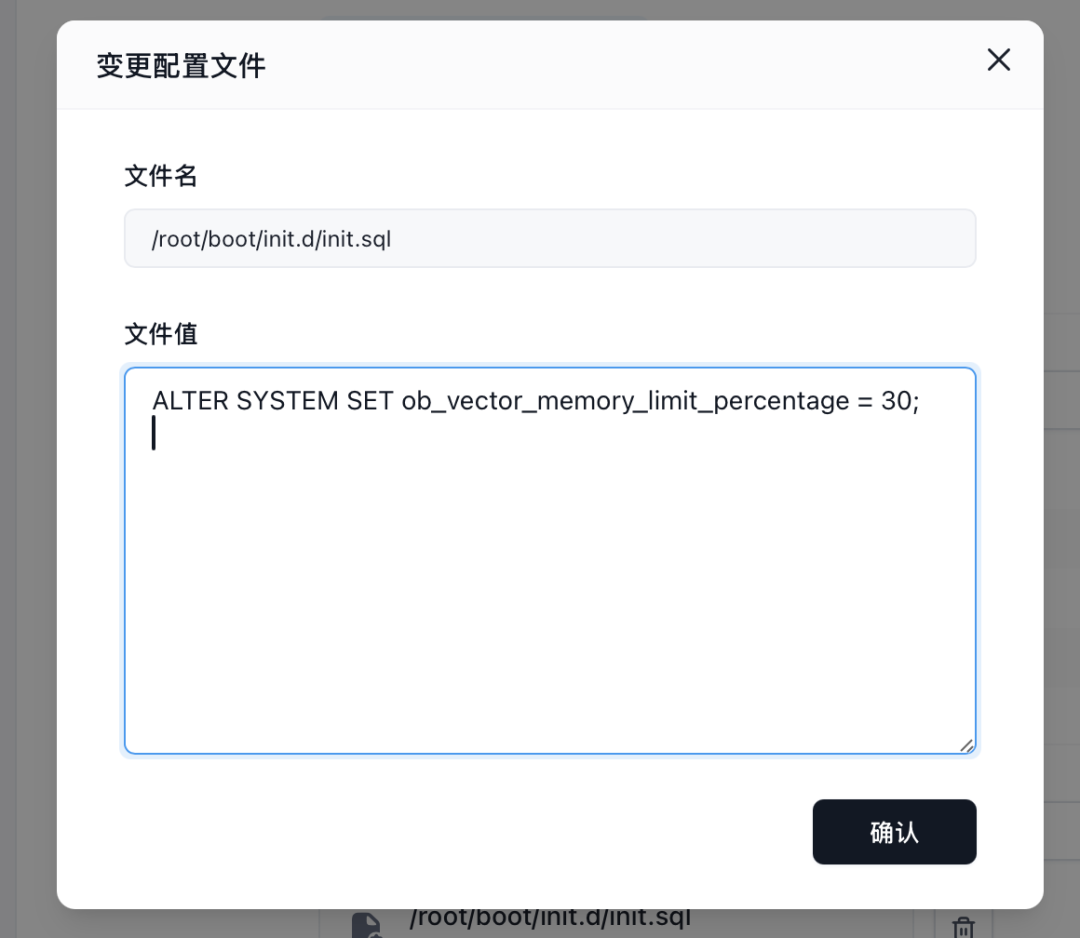
步骤五:仔细检查所有配置项
包括镜像名、资源、端口、环境变量和存储挂载路径,确保信息准确无误。
🔧 点击页面底部的 “部署” 或 “启动” 按钮。
🔧 Sealos 将开始拉取 OceanBase 镜像,并根据配置创建并启动容器。数据库启动和初始化过程可能需要一些时间。
步骤六:验证部署并连接数据库
🔔 部署成功后,在 Sealos 控制台的应用详情页面查看 OceanBase 应用实例的状态。
🔔 查看日志输出,确认 OceanBase 数据库已成功启动并完成初始化。
🔔 获取 Sealos 分配的对外访问地址(URL)和端口。
🔔 使用 OceanBase 客户端工具(如 ODC - OceanBase Developer Center 或命令行客户端 obclient)连接到该地址和端口,并使用在环境变量中设置的用户名和密码来访问和管理 OceanBase 数据库。
将 FastGPT 连接到此 OceanBase 实例
按照上述步骤成功部署并验证了 OceanBase 数据库后,接下来可以在 Sealos Cloud 上部署 FastGPT 应用,并将其配置为使用此 OceanBase 实例作为数据存储。
重要参考文档:
📕 FastGPT 官方文档:
https://doc.fastgpt.cn/docs/
📕 FastGPT GitHub Docker 示例 (OceanBase):
https://github.com/labring/FastGPT/tree/main/deploy/docker/docker-compose-oceanbase

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐

 31
31 0
0- 0



 已为社区贡献568条内容
已为社区贡献568条内容

所有评论(0)