
Vanna + Ollama + OceanBase,搭建一个AI 自然语言分析知识库系统
本文介绍如何利用 Vanna与Ollama,并基于OceanBase数据库,来打造一个AI 自然语言分析知识库系统,以及这个系统的主要功能及其所带来的好处。
* 本文转载于OceanBase博客,作者为 banjin。本文观点仅代表作者观点。
大数据时代下,人工智能技术不断发展,众多企业和研究机构纷纷开始构建自己的既高效又稳定的自然语言分析知识库系统。本文介绍如何利用 Vanna与Ollama,并基于OceanBase数据库,来打造一个AI 自然语言分析知识库系统,以及这个系统的主要功能及其所带来的好处。
一、系统架构
该系统的核心架构包括三个主要组件:Vanna、Ollama和OceanBase。
- Vanna:作为数据处理和自然语言处理(NLP)的关键组件,Vanna负责数据的预处理、清洗、转换以及NLP任务的执行,如文本分类、情感分析、实体识别等。
- Ollama:作为AI模型和算法的核心,Ollama提供了丰富的机器学习模型和深度学习算法,用于训练和优化自然语言处理任务。它与Vanna紧密集成,共同实现高效的数据分析和知识提取。
- OceanBase:作为系统的底层数据库,OceanBase提供了高可用性、强一致性和高性能的数据存储和访问能力。它确保了系统在面对大规模数据时的稳定性和可靠性。
二、系统功能
- 数据预处理与清洗:系统能够自动对输入的自然语言文本进行预处理,包括去除噪音、纠正拼写错误、分词等,以确保后续分析的准确性。
- 自然语言处理:通过Vanna和Ollama的集成,系统能够执行多种NLP任务,如文本分类、情感分析、关键词提取、实体识别等,从而提取出文本中的有用信息和知识。
- 智能分析与决策支持:基于构建的知识库,系统能够进行智能分析,为用户提供决策支持。例如,可以根据用户的查询需求,快速从知识库中检索相关信息,并生成详细的报告或建议。
三、Ollama本地大模型安装
Ollama支持win,linux,mac,本次在linux虚拟机安装,操作系统centos 7.9,内存8G
1、安装依赖包
yum install pciutils
yum install lshw否则安装会遇到WARNING: Unable to detect NVIDIA/AMD GPU. Install lspci or lshw to automatically detect and install GPU dependencies.
2、安装Ollama大模型
Download Ollama on LinuxOllama大模型下载地址:Download Ollama on Linux
官方文档上的安装方式是如下:
你可以先尝试下安装,有可能安装成功
curl -fsSL https://ollama.com/install.sh | sh 不过一般国内下载比较慢,安装过程一直卡在"»> Downloading ollama…"
可以使用如下方法
# 下载安装脚本
curl -fsSL https://ollama.com/install.sh -o o_install.sh
# 打开o_install.sh,找到以下两个下载地址:
https://ollama.com/download/ollama-linux-${ARCH}${VER_PARAM}
https://ollama.com/download/ollama-linux-amd64-rocm.tgz${VER_PARAM}
# 替换为
https://github.moeyy.xyz/https://github.com/ollama/ollama/releases/download/v0.3.2/ollama-linux-amd64
https://github.moeyy.xyz/https://github.com/ollama/ollama/releases/download/v0.3.2/ollama-linux-amd64-rocm.tgz执行安装
sh o_install.sh
localhost.localdomain:root:/root:>sh o_install.sh
>>> Installing ollama to /usr/local
>>> Downloading Linux amd64 CLI
>>> Making ollama accessible in the PATH in /usr/local/bin
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.3、下载模型
本次因为资源有限我们使用llama3.18b,下载模型模型
ollama pull llama3.1:8b
localhost.localdomain:root:/root:>ollama pull llama3.1:8b
pulling manifest
pulling 8eeb52dfb3bb... 100% ▕████████████████████████████████████████████████████████████████████▏ 4.7 GB
pulling 948af2743fc7... 100% ▕████████████████████████████████████████████████████████████████████▏ 1.5 KB
pulling 0ba8f0e314b4... 100% ▕████████████████████████████████████████████████████████████████████▏ 12 KB
pulling 56bb8bd477a5... 100% ▕████████████████████████████████████████████████████████████████████▏ 96 B
pulling 1a4c3c319823... 100% ▕████████████████████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
success
4、修改配置
检查服务
systemctl status ollama修改监听地址
#默认只能本地访问
netstat -tunlp|grep ollama
tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 23094/ollama
vim /etc/systemd/system/ollama.service
##添加如下
[Service]
Environment="OLLAMA_HOST=0.0.0.0"更改模型存放位置
vim /etc/systemd/system/ollama.service
#添加如下
[Service]
Environment="OLLAMA_MODELS=/data/ollama/models"重启 ollama
systemctl daemon-reload
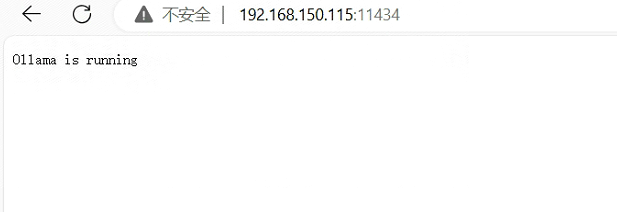
systemctl restart ollama在浏览器测试一下,确认ollama已启动
5、运行模型
我们把模型运行起来测试一下
ollama run llama3.1:8b
[root@localhost ~]# ollama run llama3.1:8b
>>>
>>>
>>> what are you doing
I'm happy to chat with you. I am a computer program designed to simulate conversation and answer questions to the best of my ability. I
don't have personal experiences or engage in physical activities like humans do.
Right now, I'm simply waiting for your next message or question. What would you like to talk about?
>>> Send a message (/? for help)
四、vanna安装配置
Vanna是一款基于开源Python框架的SQL生成工具,可以用日常用语提问,Vanna自动将其转换为SQL语句,简化数据库查询过程。
1、生成实例代码
官网:https://vanna.ai/
文档:https://vanna.ai/docs/
Vanna的例子,链接如下,按照如下图选择生成示例代码:
https://vanna.ai/docs/mysql-oll
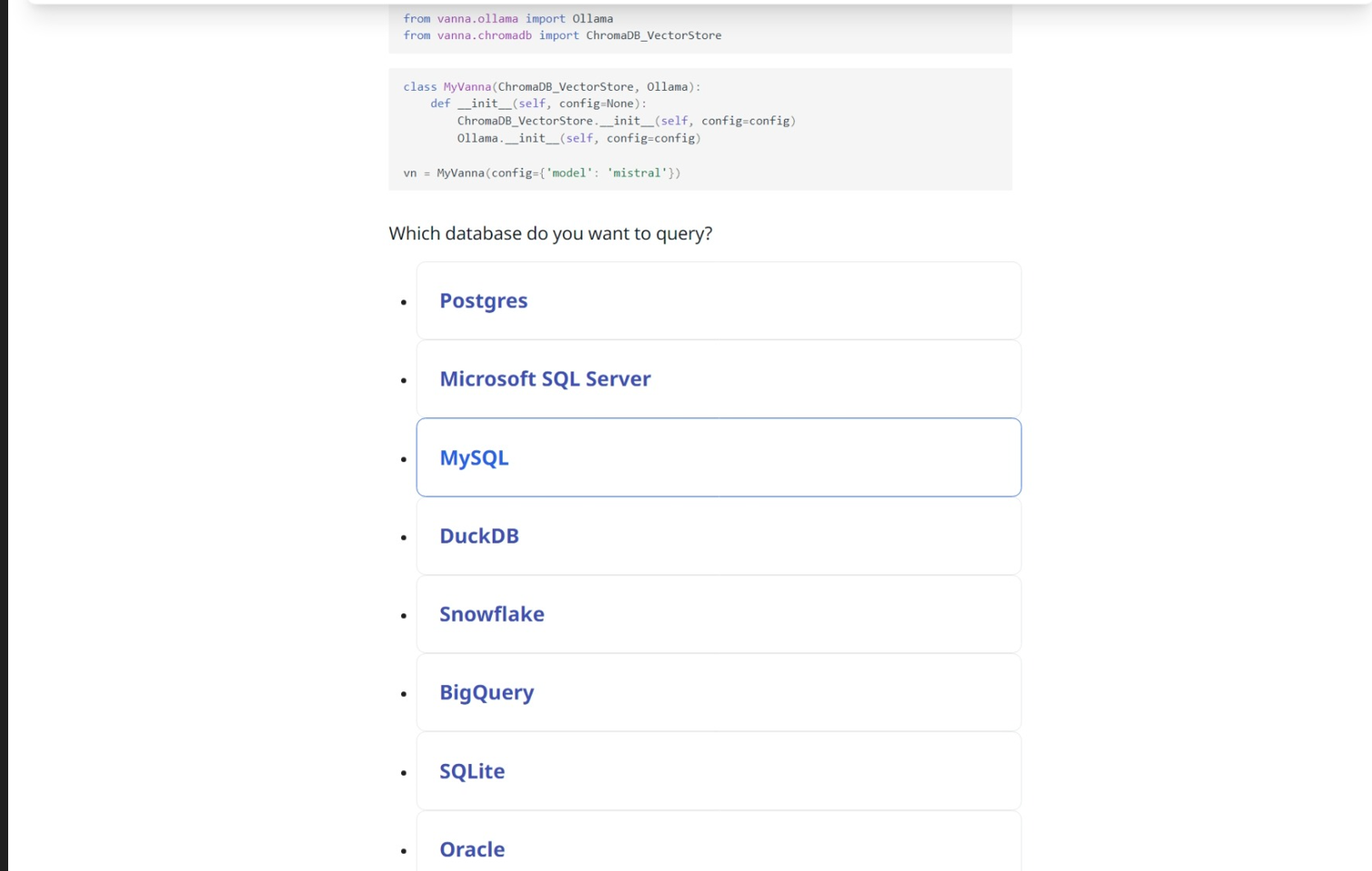
选择Ollama-ChromaDB-mysql 会生成示例代码(我用mysql租户所以选择了mysql,如果是oracle租户可以选择oracle)
2、python下安装vanna
python 安装建议3.10以上
pip install vanna[chromadb,ollama,mysql]
五、oceanbase数据库准备
可以下载 OceanBase社区版,或者开通OceanBase云数据库免费试用
附上安装文档 OceanBase 快速上手
数据库脚本
-- 分类表
CREATE TABLE knowledge_category (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '分类ID',
name VARCHAR(255) NOT NULL COMMENT '分类名称'
) COMMENT='分类表,用于存储知识点的分类信息';
-- 知识库表
CREATE TABLE knowledge_base (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '知识点ID',
title VARCHAR(255) NOT NULL COMMENT '知识点标题',
content TEXT NOT NULL COMMENT '知识点内容',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
category_id INT COMMENT '分类ID',
PRIMARY KEY (id)
) COMMENT='知识库表,用于存储知识点信息';
-- 标签表
CREATE TABLE knowledge_tag (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '标签ID',
name VARCHAR(255) NOT NULL COMMENT '标签名称'
) COMMENT='标签表,用于存储知识点的标签信息';
-- 知识点与标签关联表
CREATE TABLE knowledge_tag_relation (
knowledge_id INT NOT NULL COMMENT '知识点ID',
tag_id INT NOT NULL COMMENT '标签ID',
PRIMARY KEY (knowledge_id, tag_id)
) COMMENT='知识点与标签关联表,用于存储知识点和标签的对应关系';
-- 用户表
CREATE TABLE user (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '用户ID',
username VARCHAR(255) NOT NULL UNIQUE COMMENT '用户名',
password VARCHAR(255) NOT NULL COMMENT '密码',
email VARCHAR(255) COMMENT '邮箱'
) COMMENT='用户表,用于存储用户信息';
INSERT INTO knowledge_base (title, content, create_time, update_time, category_id) VALUES
('数据库索引原理', '详细解释数据库索引的工作原理和类型。', NOW(), NOW(), 1),
('网络安全防护策略', '介绍常见的网络安全威胁及相应的防护策略。', NOW(), NOW(), 2),
('云计算平台搭建', '指导如何搭建和配置云计算平台。', NOW(), NOW(), 3),
('深度学习模型训练', '讲解深度学习模型的训练过程和技巧。', NOW(), NOW(), 4),
('大数据分析实战', '分享大数据分析的实际案例和流程。', NOW(), NOW(), 1),
('Python编程基础', '介绍Python编程语言的基础语法和常用库。', NOW(), NOW(), 5),
('区块链技术应用', '探讨区块链技术在各行业的应用场景。', NOW(), NOW(), 1),
('自然语言处理技术', '讲解自然语言处理的基本概念和常用技术。', NOW(), NOW(), 1),
('前端框架Vue.js', '介绍Vue.js前端框架的特点和使用方法。', NOW(), NOW(), 1),
('物联网设备通信', '阐述物联网设备之间的通信协议和技术。', NOW(), NOW(), 1);
INSERT INTO knowledge_category (name) VALUES
('数据库技术'),
('网络安全'),
('云计算'),
('人工智能'),
('大数据分析');
INSERT INTO knowledge_tag (name) VALUES
('索引优化'),
('安全防护'),
('云平台'),
('深度学习'),
('数据分析');
INSERT INTO knowledge_tag_relation (knowledge_id, tag_id) VALUES
(1, 1), -- 数据库索引原理 与 索引优化 关联
(2, 2), -- 网络安全防护策略 与 安全防护 关联
(3, 3), -- 云计算平台搭建 与 云平台 关联
(4, 4), -- 深度学习模型训练 与 深度学习 关联
(5, 5), -- 大数据分析实战 与 数据分析 关联
(6, 1), -- Python编程基础(虽然不直接相关,但可视为包含索引概念) 与 索引优化 关联(示例性关联,非必须)
(7, 4), -- 区块链技术应用(可视为包含智能合约等深度学习应用) 与 深度学习 关联(示例性关联,非必须)
(8, 5), -- 自然语言处理技术 与 数据分析(虽然更偏向文本处理,但可视为一种数据分析形式)关联(示例性关联,非必须)
(9, 2), -- 前端框架Vue.js(可视为需要安全防护的Web应用) 与 安全防护 关联(示例性关联,非必须)
(10, 3); -- 物联网设备通信 与 云平台(物联网设备常接入云平台)关联(示例性关联,非必须,但更合理的可能是与“物联网”相关标签关联,此处仅为示例)
INSERT INTO user (username, password, email) VALUES
('admin', 'admin_password123', 'admin@example.com'),
('editor', 'editor_password456', 'editor@example.com'),
('user1', 'user1_password789', 'user1@example.com'),
('user2', 'user2_securepass', 'user2@example.com'),
('guest', 'guest_password000', 'guest@example.com');六、运行程序
1、python脚本
from vanna.ollama import Ollama
from vanna.chromadb import ChromaDB_VectorStore
import pandas as pd
class MyVanna(ChromaDB_VectorStore, Ollama):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
Ollama.__init__(self, config=config)
vn = MyVanna(config={'model': 'llama3.1:8b','ollama_host':'http://xx.xx.xx.xx:11434'})
vn.connect_to_mysql(host='xx.xx.xx.xx', dbname='knowledge', user='root@ob_mysql', password='xxxx', port=2881)
training_data = vn.get_training_data()
print(training_data)
vn.train(ddl="""
-- 分类表
CREATE TABLE knowledge_category (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '分类ID',
name VARCHAR(255) NOT NULL COMMENT '分类名称'
) COMMENT='分类表,用于存储知识点的分类信息';
-- 知识库表
CREATE TABLE knowledge_base (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '知识点ID',
title VARCHAR(255) NOT NULL COMMENT '知识点标题',
content TEXT NOT NULL COMMENT '知识点内容',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
category_id INT COMMENT '分类ID',
PRIMARY KEY (id)
) COMMENT='知识库表,用于存储知识点信息';
-- 标签表
CREATE TABLE knowledge_tag (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '标签ID',
name VARCHAR(255) NOT NULL COMMENT '标签名称'
) COMMENT='标签表,用于存储知识点的标签信息';
-- 知识点与标签关联表
CREATE TABLE knowledge_tag_relation (
knowledge_id INT NOT NULL COMMENT '知识点ID',
tag_id INT NOT NULL COMMENT '标签ID',
PRIMARY KEY (knowledge_id, tag_id)
) COMMENT='知识点与标签关联表,用于存储知识点和标签的对应关系';
-- 用户表
CREATE TABLE user (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '用户ID',
username VARCHAR(255) NOT NULL UNIQUE COMMENT '用户名',
password VARCHAR(255) NOT NULL COMMENT '密码',
email VARCHAR(255) COMMENT '邮箱'
) COMMENT='用户表,用于存储用户信息';
""")
from vanna.flask import VannaFlaskApp
VannaFlaskApp(vn,allow_llm_to_see_data=True).run()2、运行
在浏览器输入以上地址,运行效果,然后可以再对话窗口进行自然语言的查询了
3、智能分析
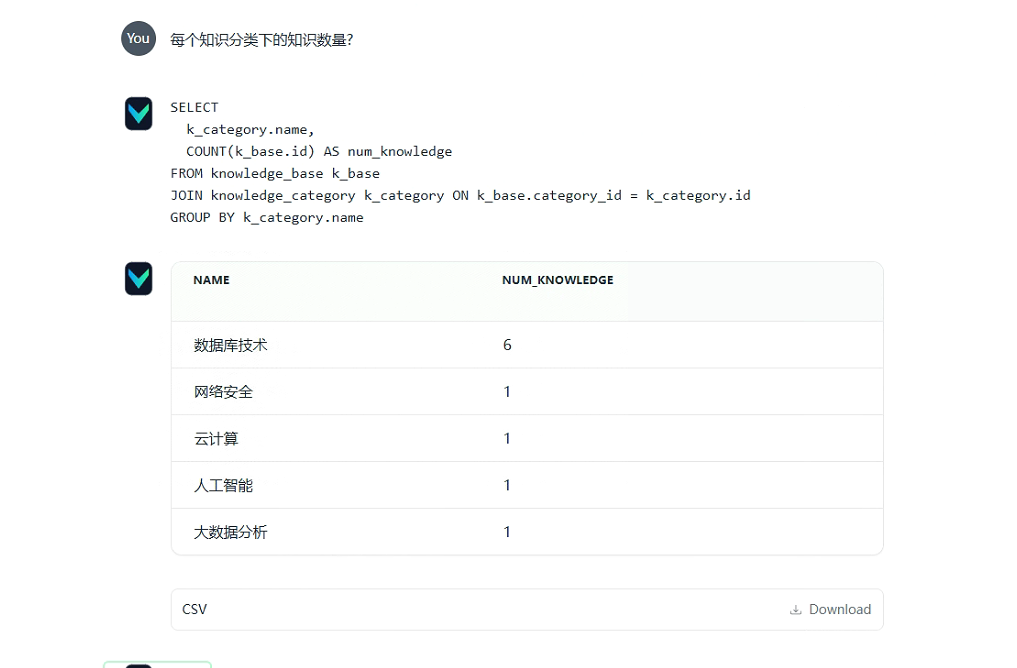
vanna会生成对应的sql然后执行对应sql并生成csv数据文件,可以进行导出
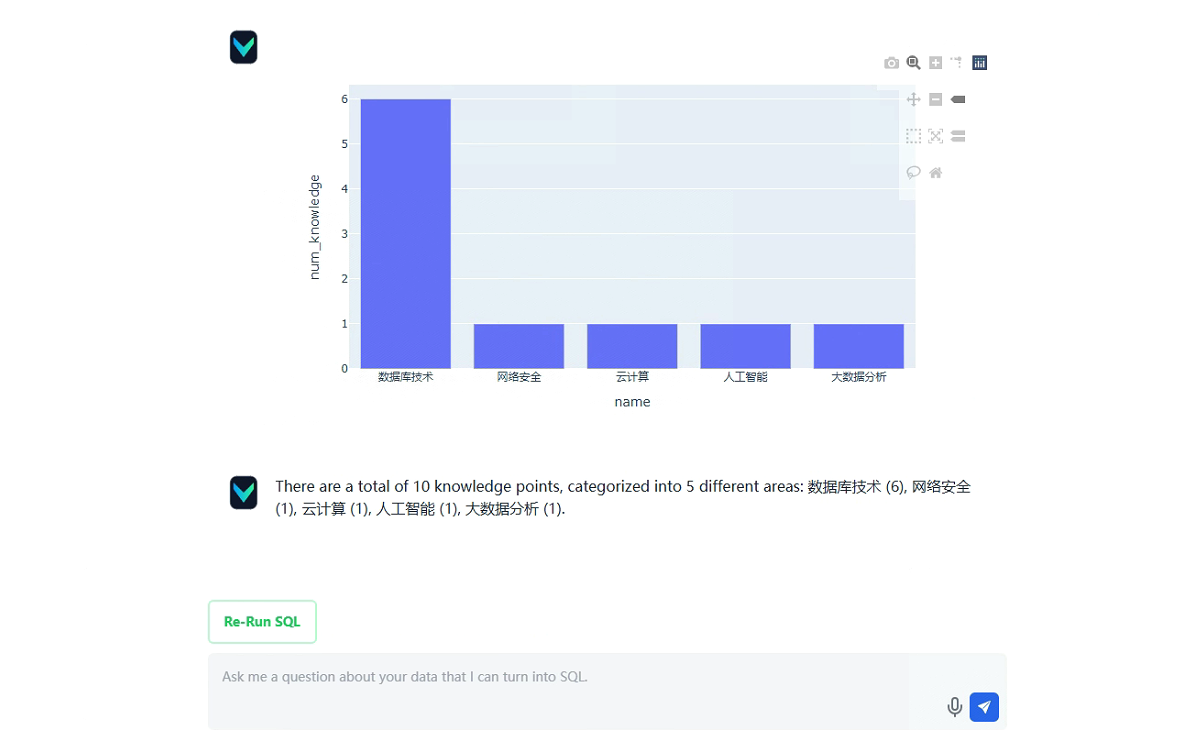
甚至会生成图表,可以根据自己的需求调整不同图表

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐

 25
25 0
0- 0



 已为社区贡献568条内容
已为社区贡献568条内容

所有评论(0)