
OceanBase + LLM,免费构建你的专属 AI 助手
本文将与大家介绍典型的 RAG 场景,探讨如何基于 OceanBase 一体化的向量能力,更加敏捷地搭建可扩展且易用的 RAG AI 助手,并分析这种架构如何简化技术栈,提升业务场景落地的效率。
随着人工智能技术的不断发展,众多企业正积极探寻将AI融入自身业务与服务之道,旨在优化用户体验并提升运营效率。这一进程中,AI应用的构建给数据基础设施带来了前所未有的挑战。AI应用往往涵盖对多样化数据类型(结构化、非结构化及半结构化数据)的存储、处理与检索,并需要更高效的数据访问和处理能力,特别是在实时响应与可扩展性方面提出了更为严苛的标准。
在近期发布的 OceanBase 4.3.3 GA 版本中,我们在关系型数据库的基础上,新增了向量检索能力,支持向量数据类型、向量索引以及基于向量索引的搜索功能。用户可以通过 SQL 和 Python SDK 两种方式,灵活地使用 OceanBase 的向量检索能力。结合 OceanBase 在海量数据分布式存储方面的优势,以及对多模数据类型和多种索引方式的支持,这一能力为用户带来更强大的数据融合查询体验,显著简化 AI 应用技术栈,加速 RAG、智能推荐、多模态搜索等场景的落地。
本文将与大家介绍典型的 RAG(Retrieval-Augmented Generation,检索增强生成)场景,探讨如何基于 OceanBase 一体化的向量能力,更加敏捷地搭建可扩展且易用的 RAG AI 助手,并分析这种架构如何简化技术栈,提升业务场景落地的效率。

1、构建AI应用面临的挑战
AI 应用对非结构化数据的存储和检索需求促进了向量数据库的发展,通过将非结构化数据 Embedding 为向量存储在向量数据库,并借助向量索引能力加速近似查询,AI 应用可以理解非结构化数据,并挖掘这些数据的语意和潜在关系。然而 AI 应用对数据的处理需求是多样,不仅涵盖非结构化数据,还包含结构化、半结构化等数据类型,同时需要支持离线批数据的导入和实时数据流的写入。
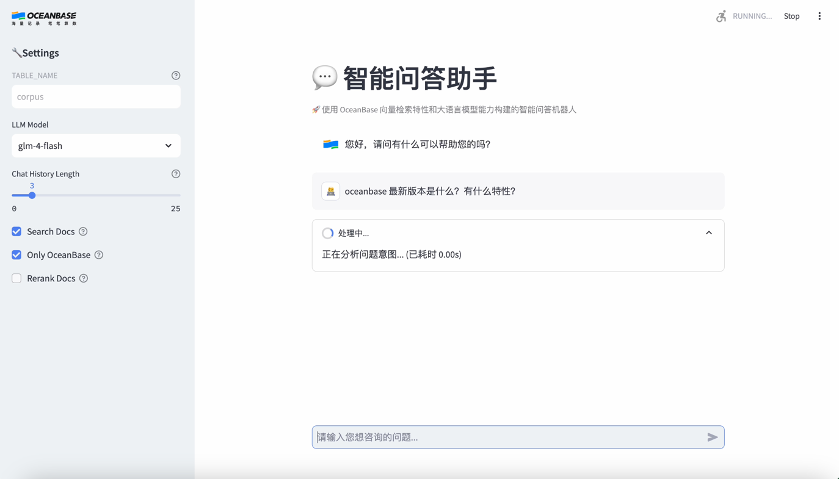
以 RAG 场景为例,我们来看看 AI 应用对数据库的需求。RAG 是一种结合信息检索与生成模型的技术,其核心思想是在生成回答之前,通过检索外部知识库中的相关信息,再结合大语言模型(LLM)生成最终的回答,从而提高回答的准确性和丰富性,因此越来越多的企业利用 RAG 技术来构建基于企业私域知识库的智能助手,OceanBase 官网最近刚上线的“AI 助手”也是如此。
RAG 应用为了提高问答的准确性,通常会同时进行向量检索和全文检索,多路查询后 rerank 得到更加准确的数据。企业的私域知识文档同时会包含诸如文档类别等多个属性,文档属性和文档内容会以结构化数据存储在数据库中,用户的问答通常也会集中的某个垂直的领域进行,需要基于文档属性进行标量过滤。因此,一个用户查询会涉及到标量过滤、向量检索、全文搜索多种检索需求。传统的 AI 应用架构需要往往接入多个数据处理系统: 使用专用的向量数据库用于存储非结构化数据,经 Embedding 后生成的向量并进行近似查询;使用 MySQL 等关系型数据库用于存储结构化数据进行标量过滤;使用 ES 等系统来进行全文检索实现模糊搜索。这种复杂的技术栈需要接入多个不同系统来满足检索需求,不同的服务提供的访问接口也是多样的,不仅存在数据冗余存储的问题,还存在多种技术栈,无形加大了 AI 应用的开发和运维难度。
2、为什么要用 OceanBase 构建RAG应用
OceanBase 以其一体化的产品能力及技术架构,为 RAG 等复杂 AI 场景提供了向量融合查询能力。最新的 4.3.3 GA 版本在原有的基础数据类型、JSON、GIS、XML、RoaringBitmap 等数据类型的基础上,新增了向量类型的支持。在二级索引、全文索引、空间索引、JSON 的多值索引的基础上支持了向量索引以加速查询。因此,只需使用一套数据库即可满足 RAG 应用对文档存储、标量过滤、向量检索、全文检索的需求,同时 OceanBase 中包含向量检索在内的各项能力均支持通过 SQL 访问,可帮助企业统一业务技术栈,简化开发流程。
同时,OceanBase 的原生分布式架构支持海量数据的水平扩展,无损数据压缩能力能够显著降低存储空间,节省应用的存储成本;高性能的写入和查询性能,则保证了 RAG 应用的实时性。
此外,私域知识库往往对数据安全和隐私有较高的要求,OceanBase 数据库已经支持比较完整的企业级安全特性,包括身份鉴别和认证、访问控制、数据加密、监控告警、安全审计,可以有效保证 AI 应用的数据安全;还提供的完备的数据库工具体系,支持数据开发、迁移、运维、诊断等数据全生命周期的管理,为 AI 应用保驾护航。
3、用 OceanBase 免费构建你的智能助手
以下是一个基于 OceanBase 的智能助手 Demo,通过该示例可以快速上手体验 OceanBase 的向量检索能力:
第一步:免费开通 OB Cloud 和 LLM 账号
OB Cloud 提供 365 天免费试用,可前往 OceanBase 官网,开通 事务型共享实例(MySQL模式)。

这个案例是用智谱大模型进行搭建,可登录其官网注册,获取 API 密钥,你也可以选择使用其他 LLM 进行搭建。
第二步:启用向量检索功能,获取数据库连接信息
进入实例工作台,设置 ob_vector_memory_limit_percentage 参数以启用向量检索功能,推荐设置值为 30。然后,单击 “连接”,获取连接串:在弹出框中选择 使用公共网络,选择 添加当前浏览器 IP 地址,填写数据库相关信息,复制连接串。
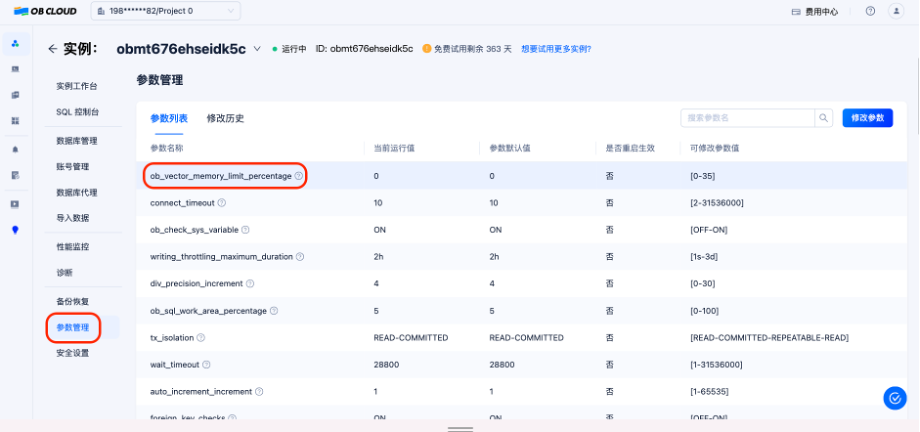
第三步:构建你的 AI 助手
1、克隆代码仓库
git clone https://gitee.com/oceanbase-devhub/ai-workshop-2024cd ai-workshop-2024
2、安装依赖和设置环境变量
3、准备 BGE-M3 模型
poetry run python utils/prepare_bgem3.py# 模型加载成功会有如下提示:# ===================================# BGEM3FlagModel loaded successfully.# ===================================
4、准备文档语料
# 克隆文档仓库cd doc_reposgit clone --single-branch --branch V4.3.3 https://github.com/oceanbase/oceanbase-doc.gitcd ..# 将标题转换为标准 Markdown 格式poetry run python convert_headings.py \doc_repos/oceanbase-doc/zh-CN \# 将文档文本 embed 为向量poetry run python embed_docs.py --doc_base doc_repos/oceanbase-doc/zh-CN
然后,就可以在你的浏览器上,向智能助手进行问答了。
4、手把手教程等你一起来
如果觉得只看上面的步骤还不够,你可以在免费开通 OB Cloud 后,通过控制台中的互动式教程进行搭建。如果觉得还不清楚,我们还为你准备了手把手的搭建课程 :
🎙 11 月 23 日,广东的朋友可以来参加 OceanBase 与 网易游戏联合举办的线下交流会 《AI 时代的数据栈建设探索与跨行业应用实践》。除了现场的 AI 实验营,还有来自游戏、教育、金融、零售等行业的技术专家分享实践经验 。快来点击预约 >>

💡 11 月 28 日,OceanBase 视频号将为你带来 《AI 动手实战营 :基于 OceanBase + LLM 打造属于你的智能助手》,下发扫码预约 。

温馨提示:参与实验前,记得准备好这些事项:
-
在 OceanBase 官网开通分析型实例的免费试用;
-
安装 Python 3.9 及以上版本;
-
安装 Poetry。

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐


 25
25 0
0- 0



 已为社区贡献691条内容
已为社区贡献691条内容

所有评论(0)