

一文看懂 OceanBase 的向量能力
本文将探讨向量数据库的技术趋势与挑战,深度解析 OceanBase的向量能力,并展示其在金融、零售、通信等行业的实际应用案例。
近年来,AI技术呈现爆发式增长,推动着各行各业新一轮技术创新与革命,数据库领域也是如此。在此背景下,向量数据库也受到越来越多的关注。
向量数据库是指通过AI大模型技术,将文本、图像、音频等非结构化的多模态数据,转化为二维向量数组进行存储和检索,从而提升了多模态数据的查询和处理效率。
本文将探讨向量数据库的技术趋势与挑战,深度解析 OceanBase的向量能力,并展示其在金融、零售、通信等行业的实际应用案例。
一、向量数据库崛起:AI 与数据库融合的新趋势
与传统侧重精准查询的 TP 和 AP 数据库不同,向量数据库依靠向量距离算法执行模糊查询,常见的算法包括曼哈顿距离算法、欧氏距离算法及余弦距离算法等。这些算法通过计算向量间的距离,在数据库中近似地查找与目标向量相似的其他向量。
简单来说,向量数据库的运作流程是先利用深度学习模型或向量嵌入模型,将多模态数据转化成二维向量数组,然后将其写入数据库。当我们发起检索或查询请求时,数据库会依据待查询的向量,在海量数据中筛选出最为相似的 top1、top10、top50 等结果,并最终结合大语言模型或其他相关模型,给出我们所需的答案。
目前,向量数据库的发展呈现两大显著趋势。与此同时,也面临着相应的技术挑战。
趋势一:数据量爆发式增长,带来非结构化数据查找难题。
随着人工智能生成内容(AIGC)的兴起,企业业务的数据增速远超以往。非结构化数据增势迅猛且呈现出三个特点:数据体量大、数据格式多样、数据理解难度高。这三个特性给数据处理提出了新的挑战,它要求数据库必须具备强大的存储能力和大量的计算资源,并能够识别、理解各类数据格式,从而实现快速精准的查询。
趋势二:向量数据库正朝着通用数据库的方向发展,旨在帮助企业实现降本增效。
未来,向量数据库的主流会是纯向量数据库还是通用数据库?这是一个值得探讨的问题。从图 1 可以直观地看出,当前市面上的向量数据库种类繁多,企业如果单独选型一款向量数据库,一方面,由于引入全新的技术栈,员工需要花费大量时间和精力学习,才能掌握新技术栈的运维和使用技巧,增加企业的培训和人力成本。另一方面,不同类型的数据分散在多个数据库中,不利于数据的整合与协同利用。
因此,很多企业更倾向于选择通用数据库。具体而言,就是在一款通用数据库中融入向量处理能力,以满足多样化的业务需求。这样不仅可以降低学习成本,避免形成数据孤岛,实现用一个技术栈存储多模态数据,还支持融合查询场景,极大地提升数据处理和分析的效率。

图 1 市面上的向量数据库概览
二、OceanBase 的向量能力:从存储到查询的技术闭环
OceanBase 凭借其强大的分布式存储能力和并行处理能力,可从容应对海量非结构化数据的处理和查询挑战,并确保系统的高可用和数据一致性。在数据类型兼容方面,OceanBase 的架构不仅可以兼容 KV 文档及向量数据,还支持 JSON、GIS、Bitmap 等多种数据类型。企业可以将所有的多模数据集中整合至单一的 OceanBase 数据库中,避免因不同类型数据存储于不同数据库而产生的数据孤岛问题。
此外,OceanBase 与 Apache Flink、Apache Spark 等众多生态工具紧密协作,可以读取其他数据库、关系型数据库管理系统(RDBMS)以及外部文件等各类数据源的数据,并将所有数据进行统一整体计算。
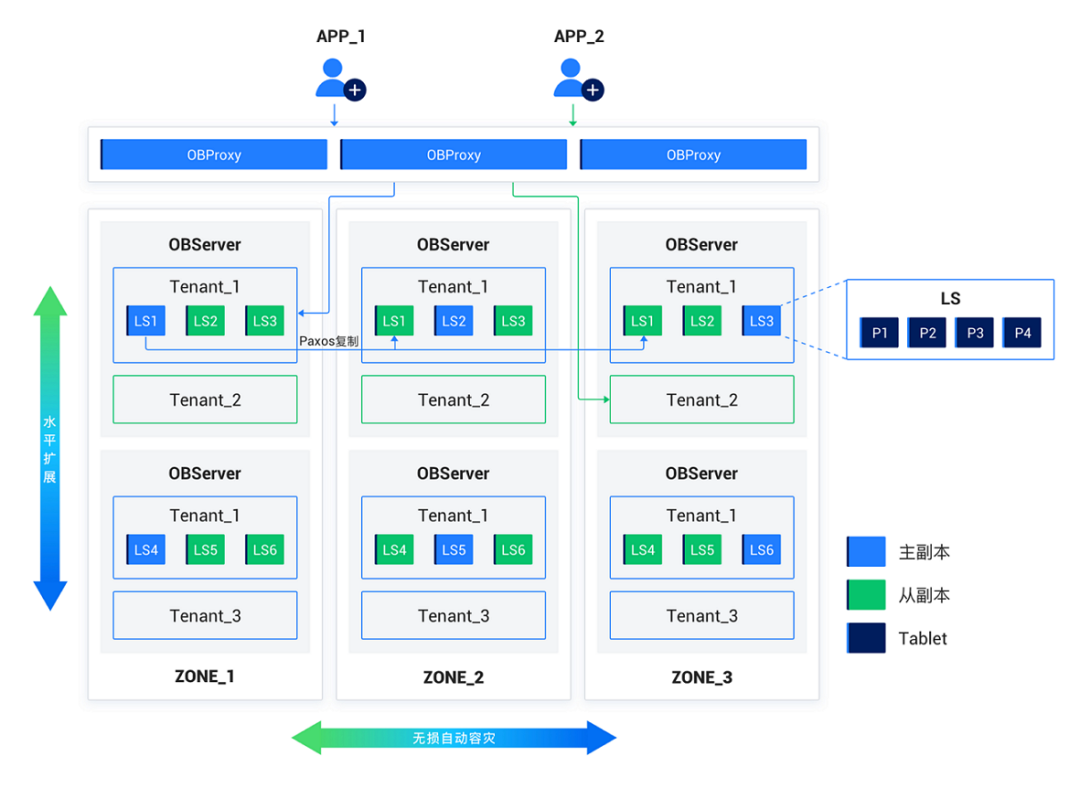
OceanBase 基于原生分布式架构,通过在存储层加入 Vector 向量数据类型,并在索引层加入向量索引,使得 OceanBase 数据库具备向量检索能力,并且这一功能拓展未对内核层及相关工具体系的使用造成影响。其整体架构如图 2 所示:

图 2 OceanBase 向量检索能力整体架构
具体而言,OceanBase 的向量能力主要体现在以下多个关键层面:
- 丰富的索引类型支持:OceanBase 不仅支持向量索引,还支持标量索引、半结构化索引(如多值索引、空间索引),以及全文索引,并且支持同时访问多路索引,为复杂的数据检索需求提供了坚实保障。
- 便捷的应用集成:OceanBase 采用 SQL 访问的方式,可复用 MySQL 生态中各语言的客户端,极大降低开发人员的学习成本。同时,OceanBase 还支持类似 Milvus SDK 的 SDK,方便用户根据自身需求灵活选择开发工具。
- 全面的索引创建语法支持:OceanBase 支持的索引类型包括 HNSW、IVFFalt、DiskANN(on processing)等多种索引类型,满足不同场景下的数据索引需求。距离算法涵盖 L2、IP、COSINE、Jaccard ( on processing)等常用距离算法,确保在向量检索时能够精准计算相似度。
- 强大的向量查询功能:OceanBase 支持 TOP N 排序的相似度计算,能够快速筛选出与目标向量最相似的结果。同时支持向量和标量混合查询,可有效应对复杂业务场景中的多元数据查询需求。
- 简单的部署运维流程:向量功能紧密集成在数据库内核中,用户可以使用部署、运维、监控及数据迁移工具,简化运维工作流程,降低运维难度。
- 简洁易用的接口设计:用户可以通过标准 SQL 语言创建向量表并写入向量数据,使用标准 SQL 语法导入向量数据并进行 DML 操作,还可以直接在对应的向量字段上创建向量索引,并指定索引类型和距离算法,利用 SQL 直接查询,操作简便直观。Python 接口只需要导入 Python 包,即可通过 Python 接口完成创建表、写入数据以及进行 ANN 等方面的检索操作,为 Python 开发者提供便捷高效的开发途径。
在使用向量数据库的业务场景中,往往需要解决的问题不是单一的,而是需要融合多种能力解决整体问题。例如,当我们要求一款软件推荐距离 500 米内、人均消费 25 元以下、评价 4.5 分以上且不用排队的奶茶店时,这一简短的需求背后,涉及到地理位置查询,以及关系型、向量型数据的检索查询。如果在不同的数据库中分别查询不同类型的数据,需要先进行多次查询,再进行结果整合,过程繁琐且耗时,最终结果的准确性也难以保证。而由于 OceanBase 支持多种数据类型,可以直接进行融合查询,从而快速准确地呈现结果。
作为一款具备向量能力的通用数据库,OceanBase 为用户带来了显著的便利。用户无需替换原有数据库,仅需对现有数据库应用进行版本升级,即可轻松获得向量能力,这一举措极大地降低了替换成本和学习成本。此外,OceanBase 的数据压缩能力,能够有效帮助用户节省数据存储成本,进一步提升了产品的性价比。
总体而言,相较于常见的向量数据库存在的稳定性不足、上手门槛高、运维复杂、周边配套不完善等问题,OceanBase 在向量场景的应用中,展现出了以下优势:
- 上手简单:接口设计简单,支持一键部署,并且高度兼容 MySQL,无论是新手还是有经验的开发者,都能快速上手使用。
- 具备金融级数据库的稳定性:OceanBase 的系统稳定性和容灾能力在多年的大规模金融场景中得到充分验证,同时,OceanBase 拥有成熟的保障体系和完整的运维工具,为系统稳定运行提供全方位支持。
- 性能强劲:OceanBase 向量检索能力集成了索引算法库 VSAG,VSAG 算法库在 960 维的 GIST 数据集上表现出色,在 ANN-Benchmarks 测试中远超其他算法。
- 成本效益显著:OceanBase 的一体化架构有效避免了在多个数据库之间做融合查询时,因需要 Rerank 后返回复杂需求而产生的高额成本,同时节省了组件之间的 RPC 调用开销。其多租户能力能够大幅提升资源利用率,帮助用户降低总体成本。
- 运维管理简单:OceanBase 提供了一套完整的运维工具体系,包括数据迁移工具 OMS、开发者工具 ODC、运维管理工具
三、简单稳定、降本增效:OceanBase 向量能力落地场景
目前,OceanBase 的向量能力已成功落地多个企业客户,应用场景主要集中在智能推荐、多模态搜索(以图搜图)、检索增强生成(RAG)等领域。
中国联通: 向量引擎助力知识库升级,硬件成本下降 30%
中国联通软件研究院数据库平台服务数百到上千的内部用户,业务范围涵盖从应用开发到运维管理的各个环节。如此庞大且复杂的数据库应用场景,给运维开发人员带来了长期且严峻的挑战。
一方面,数据库种类繁多,且版本之间差异较大,对生产系统的稳定性要求极高;另一方面,测试环境与生产环境之间的差异严重影响了工作效率。此外,日常数据库运维和管理的工作负荷繁重,提升响应速度困难重重。
为了提升运维效率和内部敏捷性,中国联通软件研究院积极探索解决方案,尝试用 RAG 架构解决上述实际问题,并成功开发出数据库智能专家“ChatDBA”。“ChatDBA”通过结合数据库领域的专业知识和联通内部的运维数据,让开发人员和 DBA 可以直接使用自然语言,对数据库状态进行查询、排查故障或获取相关建议,减少了大量重复性工作,显著提升了工作效率。
在寻找一种能够统一支持关系型数据和向量数据的解决方案时,经过综合考量与评估,中国联通软件研究院选择了 OceanBase。引入 OceanBase 后,不仅简化了技术栈,硬件资源使用量减少了约 30%,在大幅降低成本的同时,业务性能也满足了各项需求。此外,系统稳定性显著提升,单点故障风险降低,为业务的可持续发展奠定了灵活可靠且具备高度扩展性的技术基础。
想要了解更多关于 OceanBase 在中国联通软件研究院的详细落地实践内容,欢迎阅读《检索增强生成 (RAG):OceanBase 在联通软研院的落地实践》。
九机九讯云:向量检索助力 AI 导购升级购物体验显著提升
云南九机科技有限公司(简称“九机科技”)是中国最早涉足 O2O 电商领域的企业之一,自主研发了专为手机零售行业打造的系统服务 SaaS 云平台——九讯云,为零售商提供涵盖业务生态搭建、线上线下融合以及门店精细管理等全方位的数字化转型解决方案。
九机的线下门店始终将用户体验置于首位,店内陈列着款式、品牌、型号各异的海量手机。销售手机周边时,售货员在信息录入环节,由于手机壳等周边产品大部分是非标品且数量庞大,依靠肉眼比对极为耗时,张贴二维码标签的工作也极为繁重。当客户挑选产品后,售货员难以快速定位产品的 SKU 信息(如库存、价格等)。OceanBase 数据库将配件图片进行向量嵌入(Embedding)并存储(如图 3 所示),售货员只需扫描手机壳,便能快速获取手机壳信息,在线完成下单、自动减库存等一系列操作。这种以图搜图的方式,极大提高了售货员的工作效率,也提升了顾客的购物体验。
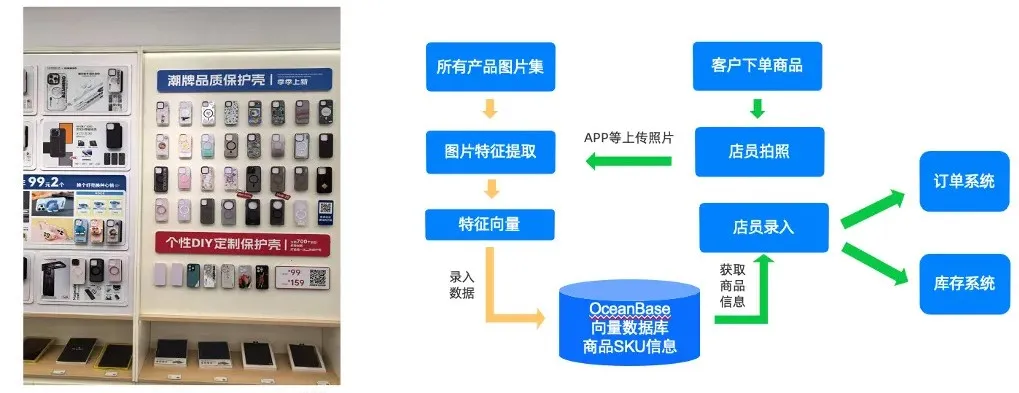
图 3 以图搜图处理过程
当各门店系统迁移至九讯云平台,需将原有系统的商品库存等信息导入九讯云系统的商品库存。然而,不同系统的商品命名差异显著,如 “苹果 15” 与 “iPhone 15”。传统的关键词匹配方式准确率低,匹配规则复杂,开发工作量巨大。九讯云调用大模型,基于 OceanBase 数据库的向量功能实现语义快速匹配(如图 4 所示),语义相似度搜索准确率提升至 90% 以上。这一举措使得商品能够快速入库,商品管理工作效率得到大幅提升。

图 4 NEO 商品匹配流程
在商品销售后端,客服、呼叫中心等部门每天需要应对消费者的各类问题。由于商品参数、活动等信息繁多,工作人员难以全部准确记忆,因此提升商品参数检索速度、加快客服响应速度至关重要。九讯云将商城手机参数等信息整理为问答形式,存入 OceanBase 向量数据库,构建便捷实用的商品问答系统(如图 5 所示),极大提高了在线客服系统与呼叫中心的工作效率,为客户带来更好的咨询体验。
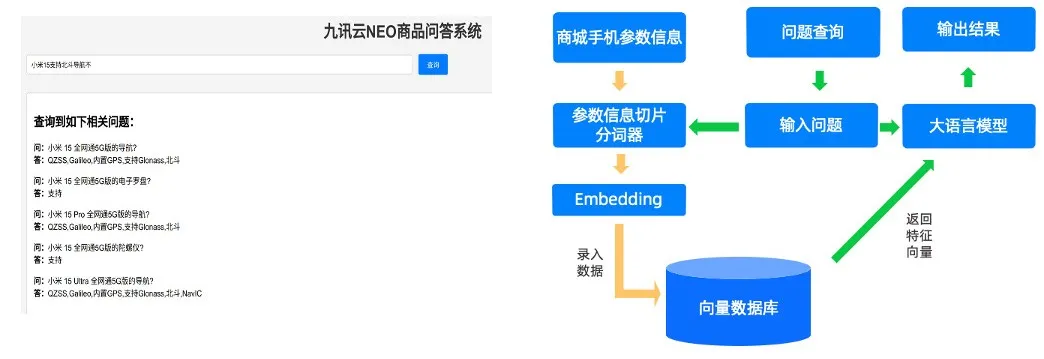
图 5 商品问答系统工作流程
2025 年 2 月,九讯云正式启动全平台智能化升级改造。鉴于 OceanBase 具备海量数据存储与处理的高性能、原生多租户数据隔离能力、数据压缩能力、KV 多模能力以及向量技术等优势,九讯云决定基于 Dify 平台 + Deepseek - R1+OceanBase 数据库的向量能力,实施全平台智能化升级改造,力求达成降本增效、技术精简、AI 赋能等目标。
更多详细内容,欢迎阅读《手机零售行业的AI破局和成本突围之路:对话九讯云技术负责人李远军》。
慧视通:向量技术助力智能交通,提升司机运营效率
慧视通深耕智能交通领域,以车联网、云计算、AI 大数据处理、无线通信和北斗全球定位技术为核心,针对巡游/网约出租车、物流/两客一危、前装新能源、驾驶培训、汽车租赁、试乘试驾等行业提供符合客户需求的产品和解决方案,为客户创造价值。
巡游出租车业务中人、证、车紧密绑定,司机运营前必须进行身份验证,确认人、证一致后方可上岗。由于机动司机需临时调度,被分配到不同出租车上驾驶,而车辆智能终端设备通常未预先存储相应司机信息,以往需出租车公司通知后台监控中心客服人员,在后台手动绑定司机信息后再下发至终端,流程繁杂且耗费人力。
引入 OceanBase 数据库的向量能力后,借助其 TOP N 排序相似度计算和标量点查功能,通过人脸识别,后台即可自动匹配司机照片,快速助力机动司机通过设备终端的身份验证,迅速上线运营,大幅提升了机动司机的运营效率。
百宝箱:向量检索应用于多业务场景,加速搜索结果呈现
支付宝的业务场景中,向量应用广泛,百宝箱就是其中之一,它为用户提供智能搜索功能,例如用户查询 3000 米以内、评分 4.5 以上、人均消费 200 以内的潮汕牛肉火锅店,系统能迅速为用户返回符合要求的目标店铺。这背后正是向量检索技术在发挥作用,并极大地加速了搜索结果的生成。
四、写在最后
在技术发展的进程中,机遇总是与挑战并存。作为 AI 技术发展与融合浪潮中的参与者,OceanBase 将持续强化技术实力,致力于为用户打造更为便捷高效的应用体验,不断开拓向量能力的全新应用场景,挖掘其更大的潜力。

了解最新的技术洞察和前沿趋势,参与 OceanBase 定期举办的线下活动,与行业开发者互动交流
更多推荐
 37
37 0
0- 0



 已为社区贡献776条内容
已为社区贡献776条内容

所有评论(0)